运行和评估流#
在 初始化和测试流 中开发和测试流之后,本指南将帮助您学习如何使用更大的数据集运行流,然后评估您创建的流。
创建批量运行#
由于您已成功使用少量数据运行流,您可能希望测试它在大数据集中的表现,您可以运行批量测试并检查输出。
批量测试允许您使用大型数据集运行流并为每个数据行生成输出,运行结果将记录在本地数据库中,因此您可以随时使用 pf 命令 查看运行结果。(例如 pf run list)
让我们使用流 web-classification 创建一个运行。这是一个演示 LLM 多分类的流。给定一个 URL,它将仅通过少量示例、简单的摘要和分类提示将 URL 分类到一个网页类别。
开始本指南,您需要
Git 克隆示例存储库(上述流链接)并将工作目录设置为
<path-to-the-sample-repo>/examples/flows/。确保您已创建必要的连接。
使用流和数据创建运行,可以添加 --stream 以流式传输运行。
pf run create --flow standard/web-classification --data standard/web-classification/data.jsonl --column-mapping url='${data.url}' --stream
请注意,column-mapping 是从流输入名称到指定值的映射,更多详细信息请参见 使用列映射。
您还可以通过在上述命令中指定 --name my_first_run 来命名运行,否则运行名称将以包含时间戳的特定模式生成。
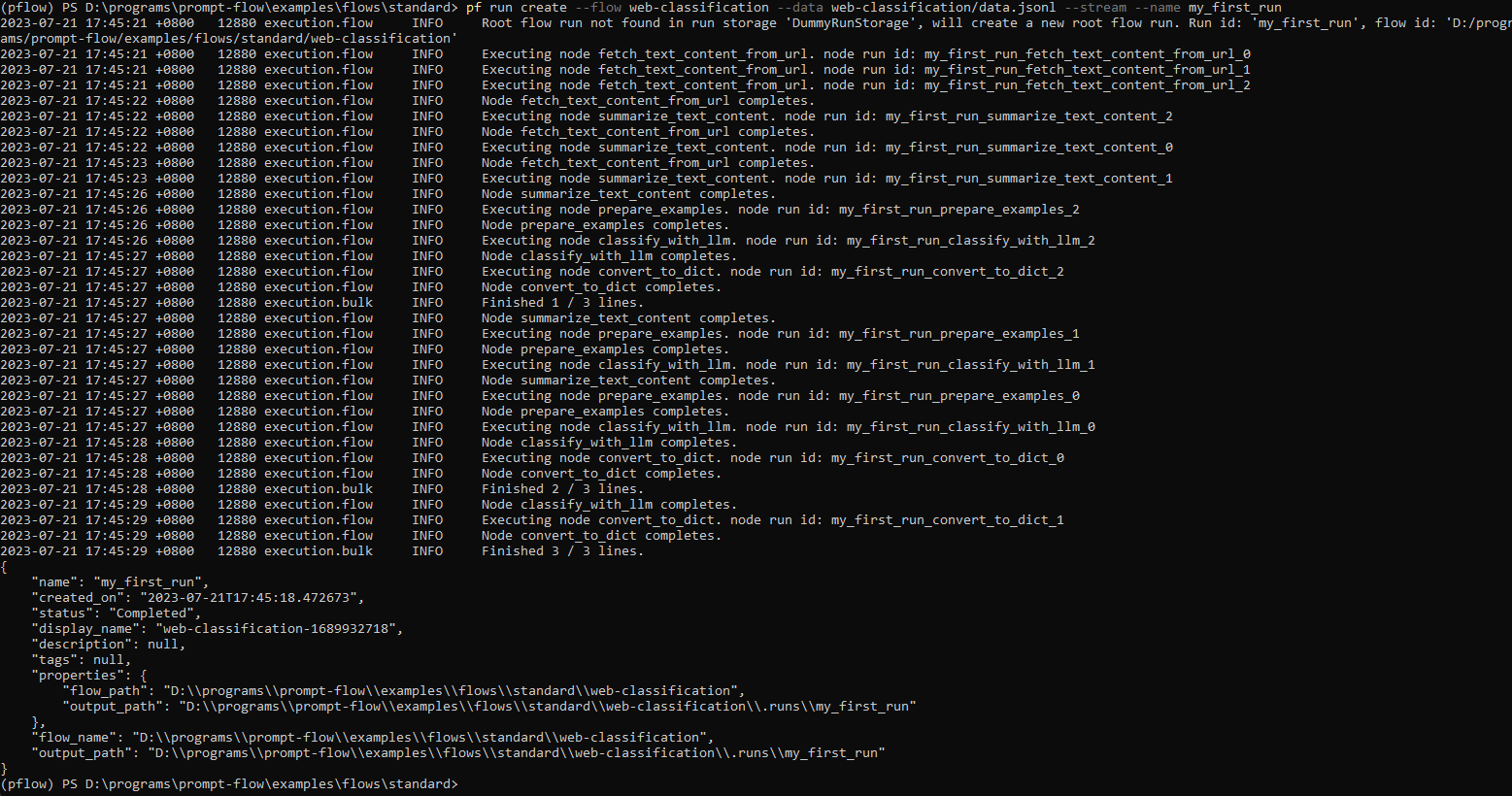
有了运行名称,您可以使用以下命令轻松查看或可视化运行详细信息
pf run show-details -n my_first_run

pf run visualize -n my_first_run
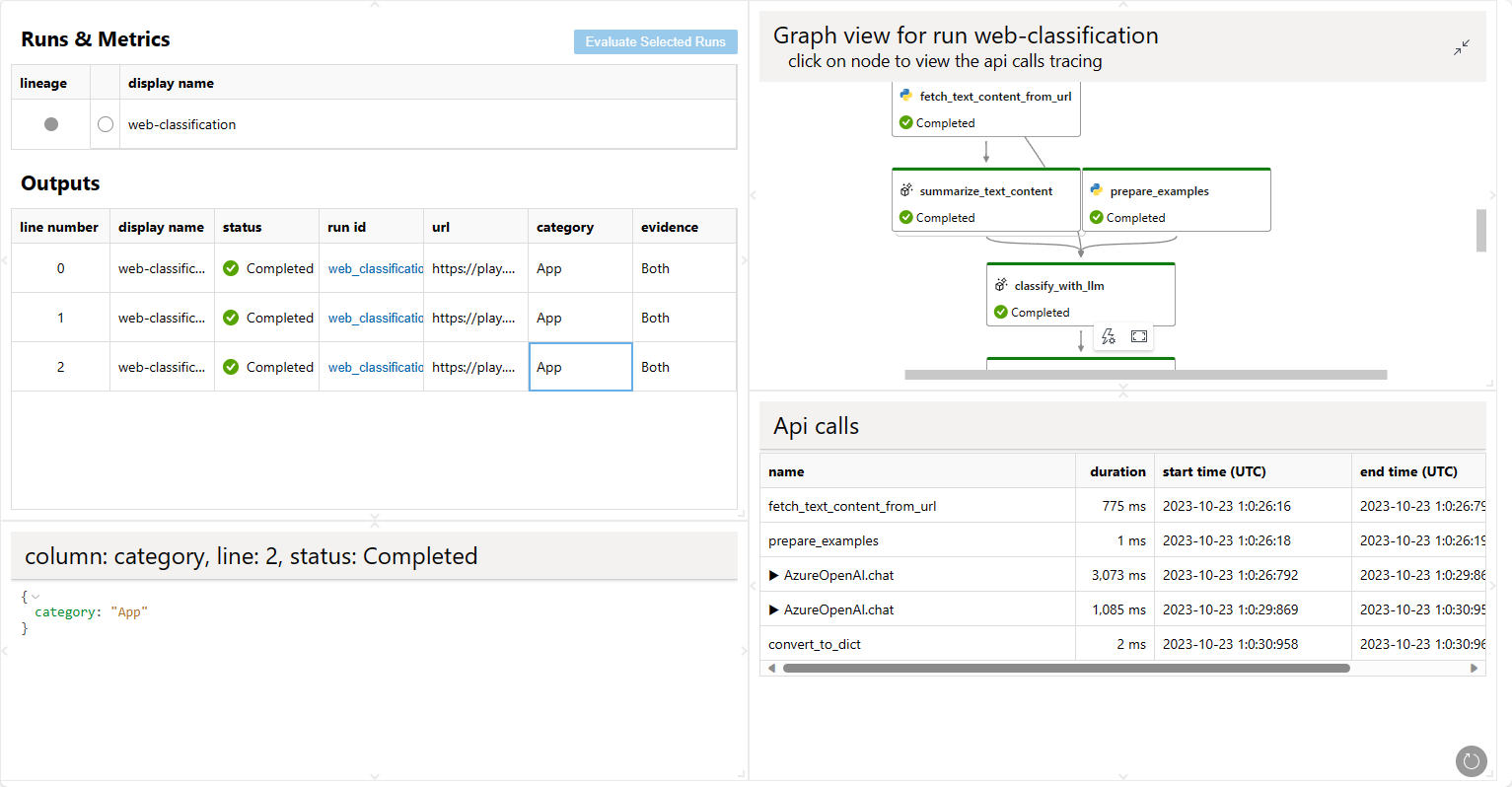
更多详细信息可以通过 pf run --help 找到
from promptflow.client import PFClient
# Please protect the entry point by using `if __name__ == '__main__':`,
# otherwise it would cause unintended side effect when promptflow spawn worker processes.
# Ref: https://docs.pythonlang.cn/3/library/multiprocessing.html#the-spawn-and-forkserver-start-methods
if __name__ == "__main__":
# PFClient can help manage your runs and connections.
pf = PFClient()
# Set flow path and run input data
flow = "standard/web-classification" # set the flow directory
data= "standard/web-classification/data.jsonl" # set the data file
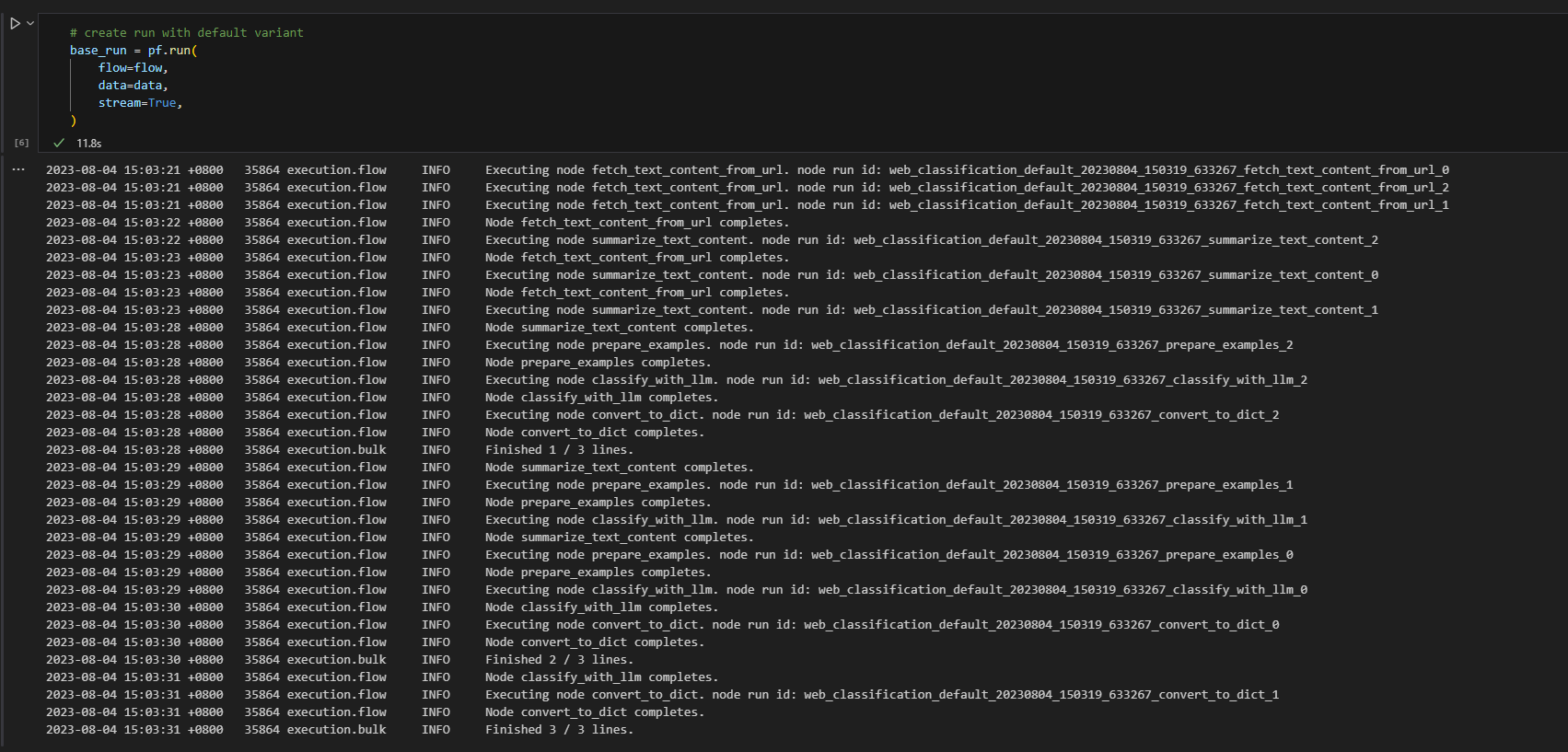
# create a run, stream it until it's finished
base_run = pf.run(
flow=flow,
data=data,
stream=True,
# map the url field from the data to the url input of the flow
column_mapping={"url": "${data.url}"},
)
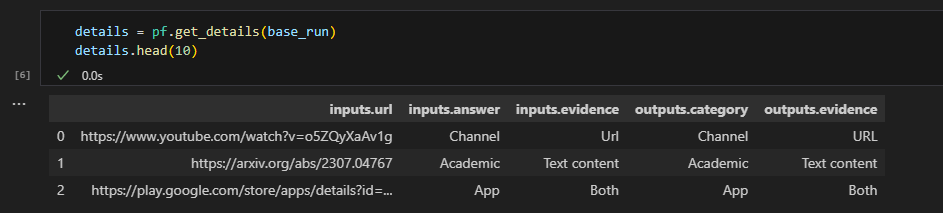
# get the inputs/outputs details of a finished run.
details = pf.get_details(base_run)
details.head(10)
# visualize the run in a web browser
pf.visualize(base_run)
请随意查看 Promptflow Python 库参考 以了解所有 SDK 公共接口。
使用 yaml 编辑器顶部的代码透镜操作触发批量运行 
单击可视化编辑器顶部的批量测试按钮触发流测试。 
我们还有更详细的文档 管理运行,演示如何使用 CLI、SDK 和 VS Code 扩展管理已完成的运行。
评估您的流#
您可以使用评估方法评估您的流。评估方法也是使用 Python 或 LLM 等计算准确度、相关性分数等指标的流。请参阅 开发评估流 了解如何开发评估流。
在本指南中,我们使用 eval-classification-accuracy 流进行评估。这是一个演示如何评估分类系统性能的流。它涉及将每个预测与真实值进行比较,并分配 Correct 或 Incorrect 等级,并聚合结果以生成 accuracy 等指标,这反映了系统在分类数据方面的表现。
针对运行运行评估流#
评估已完成的流运行
运行完成后,您可以使用以下命令评估运行,与正常的运行创建命令相比,请注意有两个额外的参数
column-mapping:从流输入名称到指定数据值的映射。有关详细信息,请参阅 此处。run:要评估的流运行的运行名称。
更多详细信息可以在 使用列映射 中找到。
pf run create --flow evaluation/eval-classification-accuracy --data standard/web-classification/data.jsonl --column-mapping groundtruth='${data.answer}' prediction='${run.outputs.category}' --run my_first_run --stream
与之前的运行相同,您可以使用上述命令中的 --name my_first_eval_run 指定评估运行名称。
您还可以使用以下命令流式传输或查看运行详细信息
pf run stream -n my_first_eval_run # same as "--stream" in command "run create"
pf run show-details -n my_first_eval_run
pf run show-metrics -n my_first_eval_run
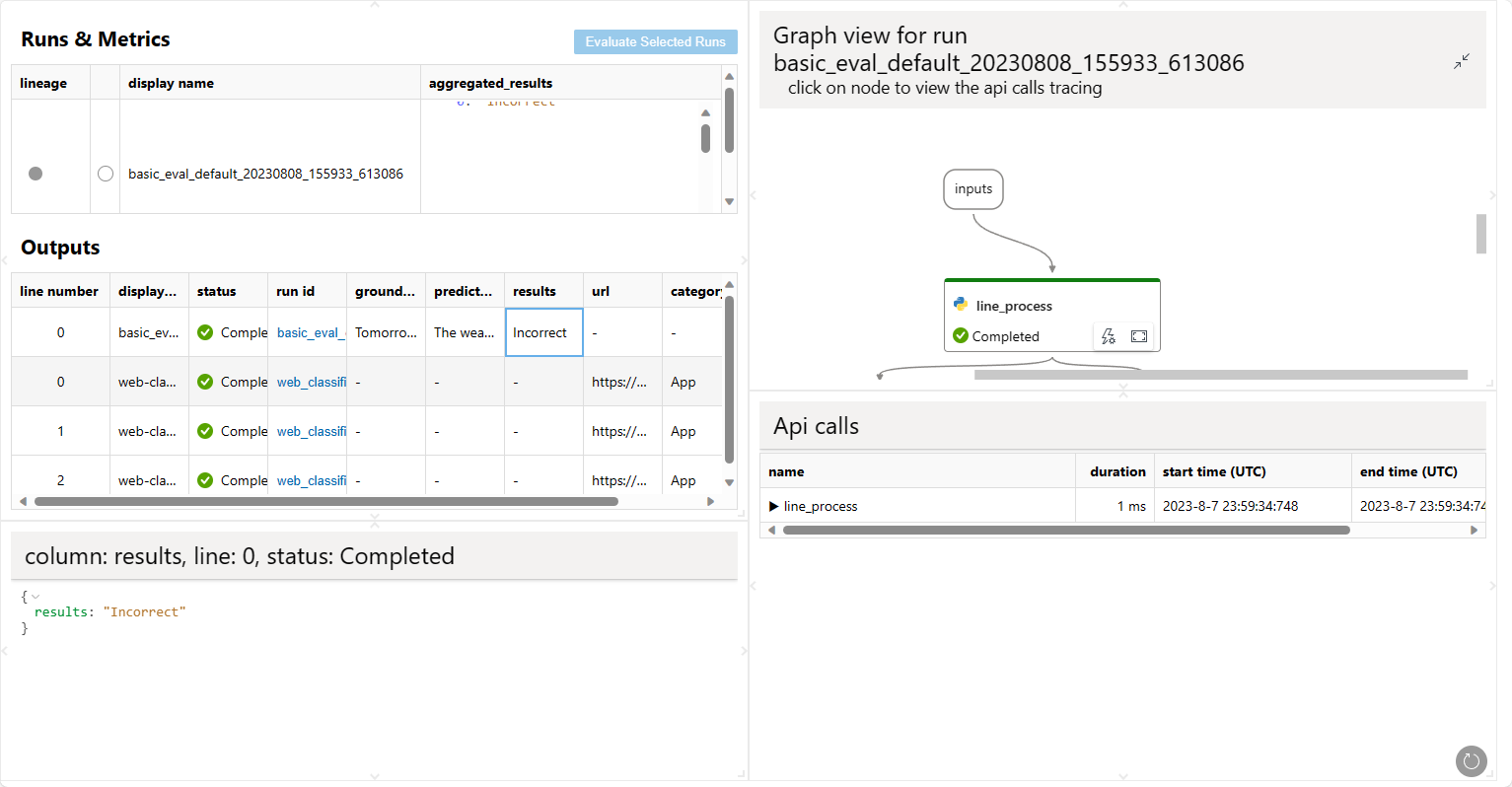
由于现在您有两个不同的运行 my_first_run 和 my_first_eval_run,您可以使用以下命令同时可视化这两个运行。
pf run visualize -n "my_first_run,my_first_eval_run"
将打开一个网页浏览器以显示可视化结果。
评估已完成的流运行
运行完成后,您可以使用以下命令评估运行,与正常的运行创建命令相比,请注意有两个额外的参数
column-mapping:一个字典,表示评估方法所需输入数据源。数据源可以来自流运行输出或您的测试数据集。如果数据列在您的测试数据集中,则指定为
${data.<column_name>}。如果数据列来自您的流输出,则指定为
${run.outputs.<output_name>}。
run:要评估的流运行的运行名称或运行实例。
更多详细信息可以在 使用列映射 中找到。
from promptflow.client import PFClient
# PFClient can help manage your runs and connections.
pf = PFClient()
# set eval flow path
eval_flow = "evaluation/eval-classification-accuracy"
data= "standard/web-classification/data.jsonl"
# run the flow with existing run
eval_run = pf.run(
flow=eval_flow,
data=data,
run=base_run,
column_mapping={ # map the url field from the data to the url input of the flow
"groundtruth": "${data.answer}",
"prediction": "${run.outputs.category}",
}
)
# stream the run until it's finished
pf.stream(eval_run)
# get the inputs/outputs details of a finished run.
details = pf.get_details(eval_run)
details.head(10)
# view the metrics of the eval run
metrics = pf.get_metrics(eval_run)
print(json.dumps(metrics, indent=4))
# visualize both the base run and the eval run
pf.visualize([base_run, eval_run])
将打开一个网页浏览器以显示可视化结果。
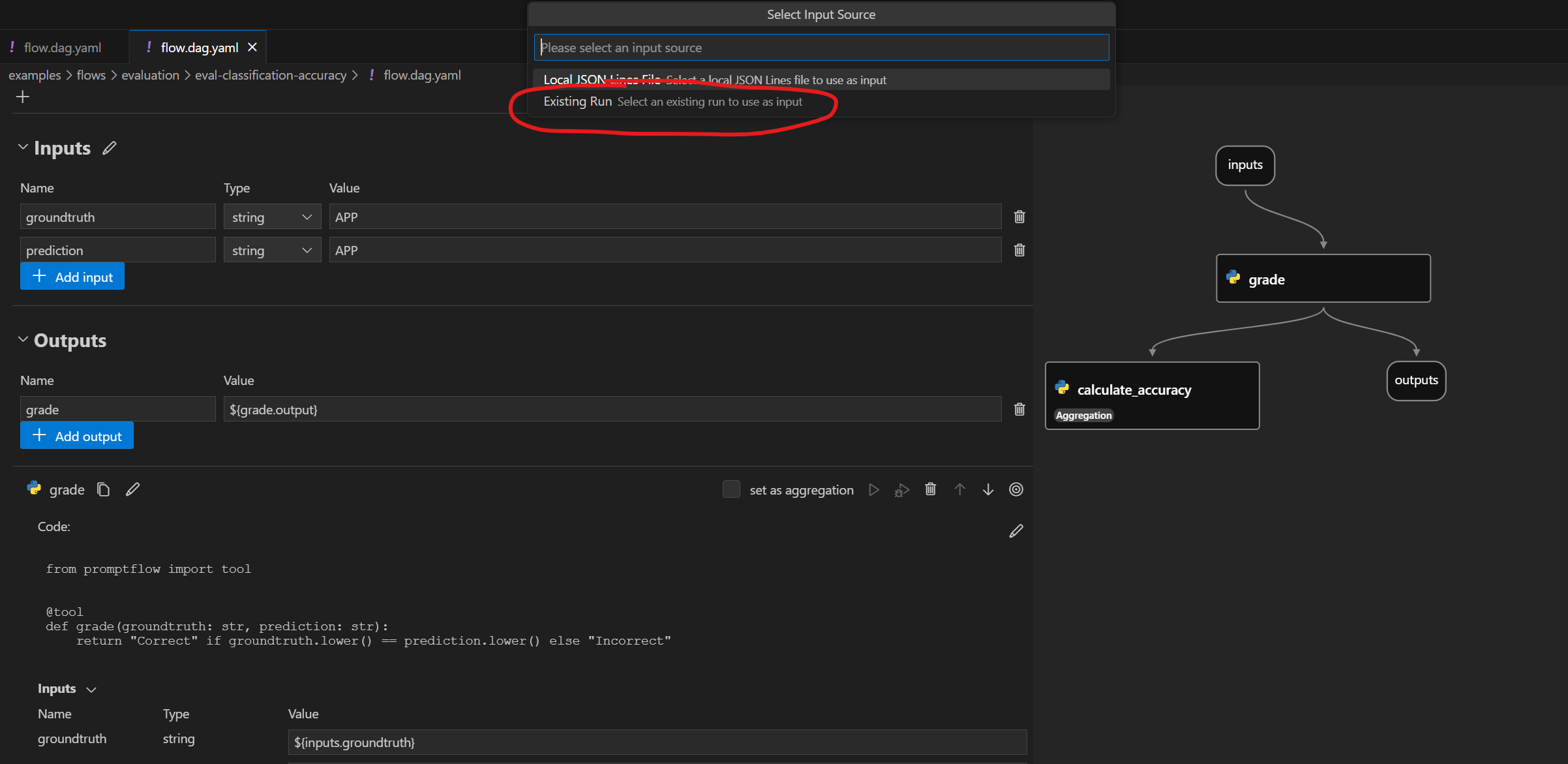
有触发本地批量运行的操作。要执行评估,您可以使用针对“现有运行”的操作。
后续步骤#
了解更多关于