开发评估流#
评估流是用于测试/评估您的 LLM 应用程序(标准/聊天流)质量的流程。它通常在标准/聊天流的输出上运行,并计算可用于确定标准/聊天流是否表现良好的关键指标。有关更多信息,请参阅流。
在继续阅读本文档之前,了解标准流非常重要。请务必阅读开发标准流,因为它们共享许多共同的功能,并且这些功能不会在此文档中重复,例如:
输入/输出 定义节点流中的 链式 节点
虽然评估流与标准流有相似之处,但也有一些重要的区别。主要区别如下:
来自现有运行的输入:评估流包含从标准/聊天流的输出派生的输入。这些输入用于评估目的。聚合节点:评估流包含一个或多个聚合节点,实际评估在此处进行。这些节点负责计算指标并确定标准/聊天流的性能。
评估流示例#
在本指南中,我们使用eval-classification-accuracy流作为评估流的示例。这是一个说明如何评估分类流性能的流程。它涉及将每个预测与真实值进行比较,并分配正确或不正确的等级,并聚合结果以生成诸如准确性之类的指标,这反映了系统在分类数据方面的能力。
流输入#
流eval-classification-accuracy包含两个输入:
inputs:
groundtruth:
type: string
description: Groundtruth of the original question, it's the correct label that you hope your standard flow could predict.
default: APP
prediction:
type: string
description: The actual predicted outputs that your flow produces.
default: APP
从输入描述中可以看出,评估流需要两个特定的输入:
groundtruth:此输入表示将用于评估标准/聊天流性能的实际或预期值。prediction:预测输入从另一个标准/聊天流的输出派生。它包含由标准/聊天流生成的预测值,这些值将在评估过程中与真实值进行比较。
从定义角度来看,与在标准/聊天 流中添加输入/输出没有区别。但是,在运行评估流时,您可能需要指定来自数据文件和流运行输出的数据源。有关更多详细信息,请参阅运行和评估流。
聚合节点#
在介绍聚合节点之前,让我们看看常规节点是什么样的,我们以示例流中的节点grade为例:
- name: grade
type: python
source:
type: code
path: grade.py
inputs:
groundtruth: ${inputs.groundtruth}
prediction: ${inputs.prediction}
它从流输入中获取groundtruth和prediction,并在源代码中比较它们是否匹配。
from promptflow.core import tool
@tool
def grade(groundtruth: str, prediction: str):
return "Correct" if groundtruth.lower() == prediction.lower() else "Incorrect"
当谈到聚合节点时,它与常规节点有两个关键区别:
它的属性
aggregation设置为true。
- name: calculate_accuracy
type: python
source:
type: code
path: calculate_accuracy.py
inputs:
grades: ${grade.output}
aggregation: true # Add this attribute to make it an aggregation node
其源代码接受一个
List类型参数,该参数是先前常规节点输出的集合。
from typing import List
from promptflow.core import log_metric, tool
@tool
def calculate_accuracy(grades: List[str]):
result = []
for index in range(len(grades)):
grade = grades[index]
result.append(grade)
# calculate accuracy for each variant
accuracy = round((result.count("Correct") / len(result)), 2)
log_metric("accuracy", accuracy)
return result
上述函数中的参数grades包含由常规节点grade产生的所有结果。假设引用的标准流运行有3个输出:
{"prediction": "App"}
{"prediction": "Channel"}
{"prediction": "Academic"}
我们提供了一个这样的数据文件:
{"groundtruth": "App"}
{"groundtruth": "Channel"}
{"groundtruth": "Wiki"}
那么grades的值将是["Correct", "Correct", "Incorrect"],最终准确性为0.67。
此示例提供了如何评估分类流的直接演示。一旦您对评估机制有了扎实的理解,您就可以根据您的特定需求定制和设计自己的评估方法。
关于列表参数的更多信息#
如果引用的标准流运行输出的数量与提供的数据文件不匹配怎么办?我们知道标准流可以针对多行数据执行,其中一些可能失败,而另一些则成功。考虑上面示例中提到的相同标准流运行,但第2行运行失败,因此我们有以下运行输出:
{"prediction": "App"}
{"prediction": "Academic"}
promptflow 流执行器能够识别引用运行输出的索引并从提供的数据文件中提取相应的数据。这意味着在执行过程中,即使提供了相同的数据文件(3行),也只处理下面提到的特定数据:
{"groundtruth": "App"}
{"groundtruth": "Wiki"}
在这种情况下,grades的值将是["Correct", "Incorrect"],准确性为0.5。
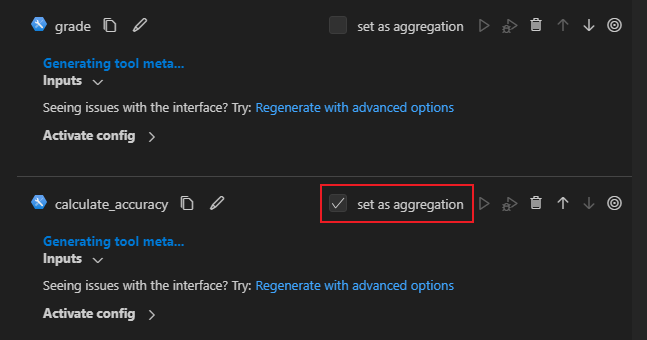
如何在 VS Code 扩展中设置聚合节点#
如何记录指标#
限制
您只能在聚合节点中记录指标,否则指标将被忽略。
Promptflow 支持使用log_metric函数记录和跟踪实验。指标是记录单个浮点度量的键值对。在 python 节点中,您可以使用以下代码记录指标:
from typing import List
from promptflow.core import log_metric, tool
@tool
def example_log_metrics(grades: List[str]):
# this node is an aggregation node so it accepts a list of grades
metric_key = "accuracy"
metric_value = round((grades.count("Correct") / len(result)), 2)
log_metric(metric_key, metric_value)
运行完成后,您可以运行pf run show-metrics -n <run_name>查看指标。
