评估 Garnet 的性能优势
我们已经在各种部署模式下对 Garnet 进行了全面测试
- 客户端和服务器在同一本地机器上
- 两台本地机器 - 一台客户端,一台服务器
- Azure Windows 虚拟机
- Azure Linux 虚拟机
下面,我们重点介绍一些关键结果。
设置
我们配置了两台运行 Linux (Ubuntu 20.04) 的 Azure Standard F72s v2 虚拟机(每台 72 个 vcpu,144 GiB 内存),并启用了加速 TCP。此 SKU 的优势在于我们保证不会与其他 VM 共置,这将优化性能。一台机器运行不同的缓存存储服务器,另一台机器专门用于发布工作负载。我们使用名为 Resp.benchmark 的基准测试工具生成所有结果。我们将 Garnet 与撰写本文时 Redis (v7.2)、KeyDB (v6.3.4) 和 Dragonfly (v6.2.11) 的最新开源版本进行比较。在这些实验中,我们使用统一的随机密钥分布(Garnet 的共享内存设计在偏斜工作负载下表现更佳)。所有数据都适合这些实验的内存。基线系统根据可用信息进行了尽可能多的调整和优化。下面,我们总结了每个系统用于我们实验的启动配置。
Garnet
dotnet run -c Release --framework=net8.0 --project Garnet/main/GarnetServer -- \
--bind $host \
--port $port \
--no-pubsub \
--no-obj \
--index 1g
Redis 7.2
./redis-server \
--bind $host \
--port $port \
--logfile "" \
--save "" \
--appendonly no \
--protected-mode no \
--io-threads 32
KeyDB 6.3.4
./keydb-server \
--bind $host \
--port $port \
--logfile "" \
--protected-mode no \
--save "" \
--appendonly no \
--server-threads 16 \
--server-thread-affinity true
Dragonfly 6.2.11
./dragonfly \
--alsologtostderr \
--bind $host \
--port $port \
--df_snapshot_format false \
--dbfilename "" \
--max_client_iobuf_len 10485760
基本命令性能
我们通过改变有效载荷大小、批量大小和客户端线程数来测量基本 GET/SET 操作的吞吐量和延迟。对于吞吐量实验,我们在运行实际工作负载之前将一个小数据库(1024 个键)和一个大数据库(2.56 亿个键)预加载到 Garnet 中。相比之下,我们的延迟实验是在空数据库上进行的,并且针对在小键空间(1024 个键)上操作的 GET/SET 命令的组合工作负载。
GET 吞吐量
对于图 1 中描述的实验,我们使用了大批量的 GET 操作(每批 4096 个请求)和小型有效载荷(8 字节键和值)以最大程度地减少网络开销。随着客户端会话数量的增加,我们观察到 Garnet 表现出比 Redis 或 KeyDB 更好的可扩展性。Dragonfly 表现出类似的可扩展性特征,尽管只达到 16 个线程。另请注意,DragonFly 是一个纯内存系统。总体而言,即使数据库大小(即预加载的不同键的数量)大于处理器缓存大小(达到 2.56 亿个键),Garnet 相对于其他系统的吞吐量也始终更高。
改变客户端会话数或批量大小 (GET)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op GET \
--keylength 8 \
--valuelength $valuelength \
--threads 1,2,4,8,16,32,64,128 \
--batchsize $batchsize \
--dbsize $dbsize
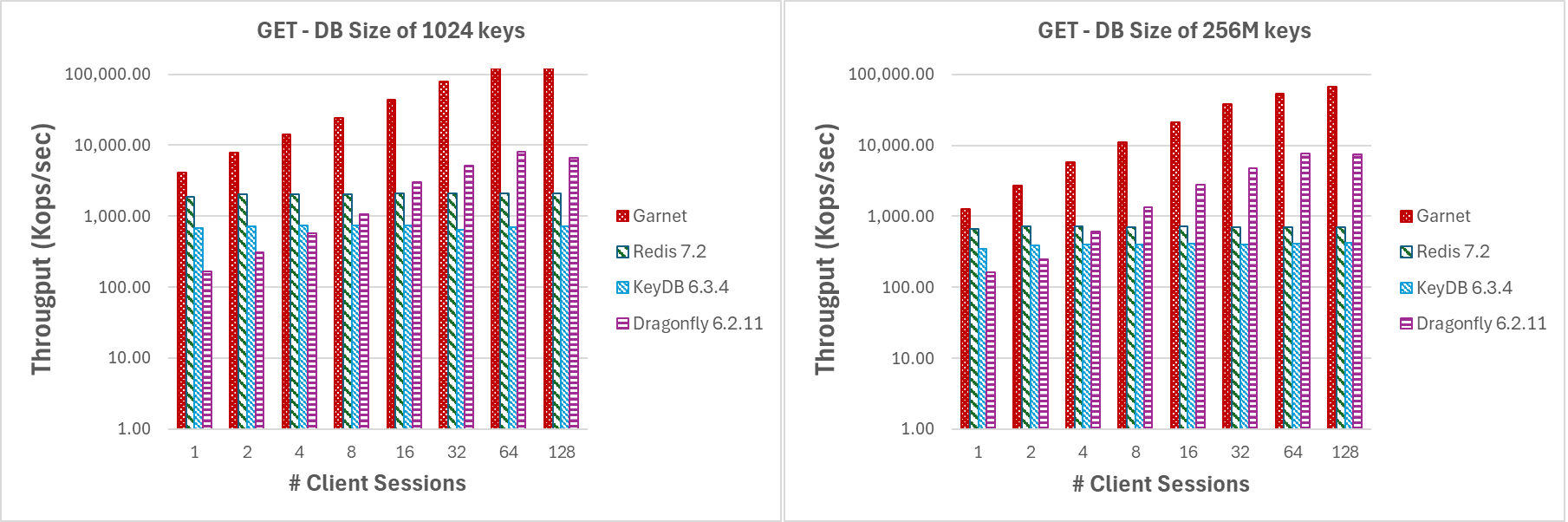 |
|---|
| 图 1:吞吐量(对数刻度),客户端会话数量变化,数据库大小为 (a) 1024 个键,和 (b) 2.56 亿个键 |
即使是小批量,Garnet 也始终保持更高的吞吐量,从而超越竞争系统,如图 2 所示。这与实际数据库大小无关。
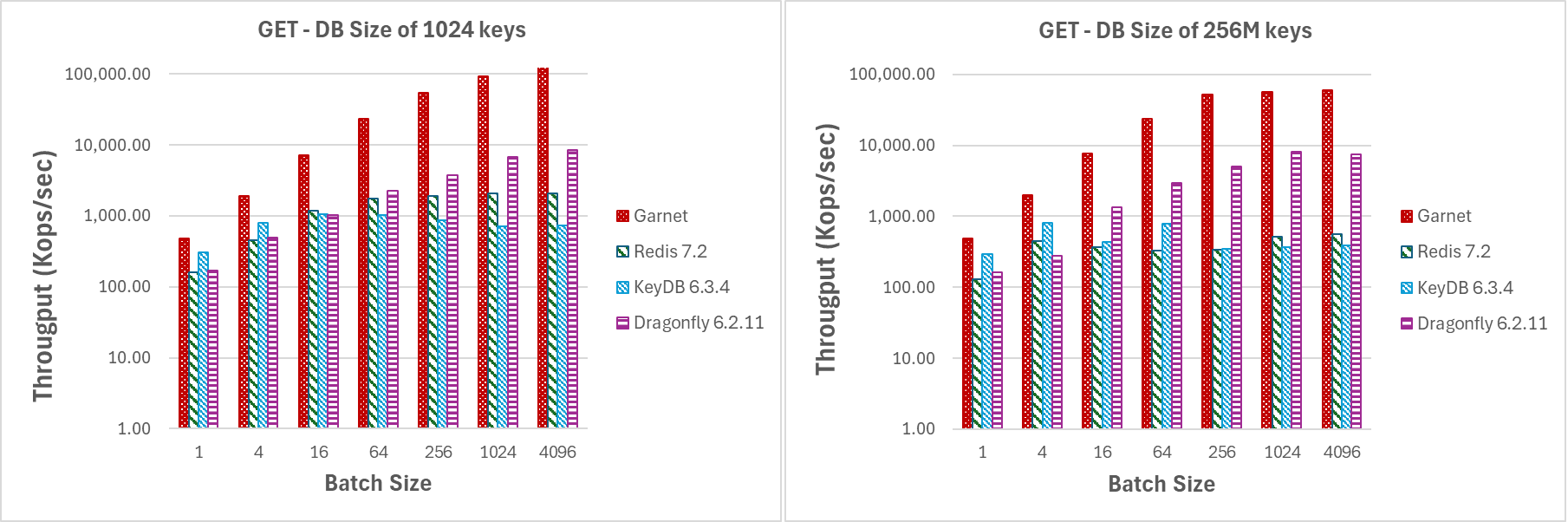 |
|---|
| 图 2:吞吐量(对数刻度),批量大小变化,数据库大小为 (a) 1024 个键,和 (b) 2.56 亿个键 |
GET/SET 延迟
接下来,我们通过发出 80% GET 和 20% SET 请求的混合请求来测量各种系统的客户端延迟,并将其与 Garnet 进行比较。由于我们关心延迟,因此我们保持数据库大小较小,同时改变工作负载的其他参数,例如客户端线程、批量大小和有效载荷大小。
图 3 展示了随着客户端会话数量的增加,Garnet 的延迟(以微秒为单位测量)以及在各种百分位数上始终低于其他系统且更稳定。请注意,此实验未使用批处理。
延迟基准测试,改变客户端会话数或批量大小 (GET/SET)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark
--host $host \
--port $port \
--batchsize 1 \
--threads $threads \
--client GarnetClientSession \
--runtime 35 \
--op-workload GET,SET \
--op-percent 80,20 \
--online \
--valuelength $valuelength \
--keylength $keylength \
--dbsize 1024 \
--itp $batchsize
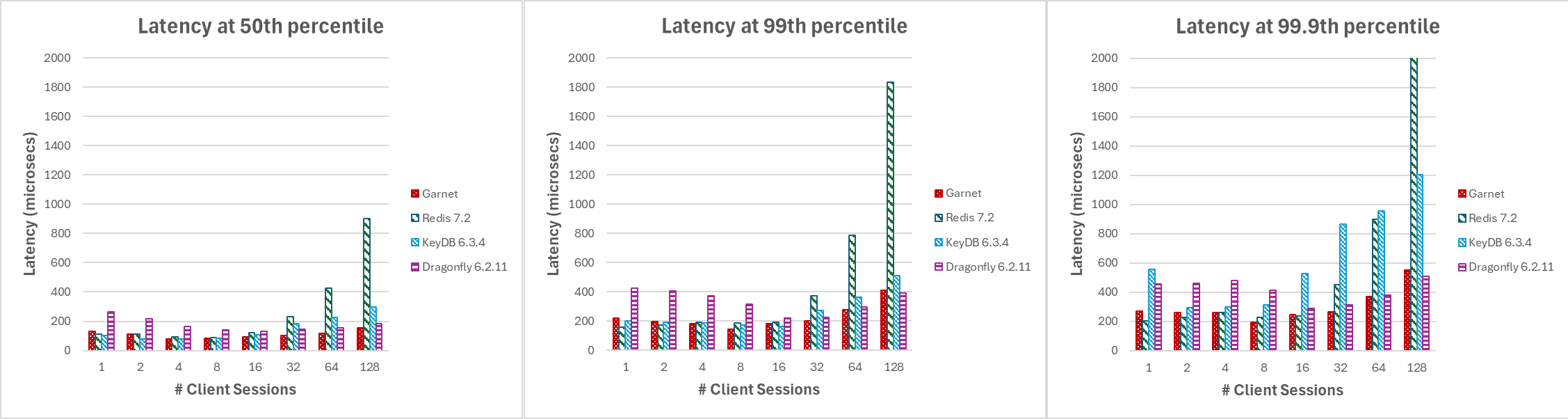 |
|---|
| 图 3:延迟,客户端会话数量变化,在 (a) 中位数,(b) 99 百分位数,和 (c) 99.9 百分位数 |
Garnet 的延迟经过精细调整,可实现自适应客户端批处理并有效处理查询系统的多个会话。对于我们的下一组实验,我们将批量大小从 1 增加到 64,并绘制了以下在 128 个活动客户端连接下不同百分位数的延迟。如图 4 所示,当批量大小增加时,Garnet 保持稳定性并实现比其他系统更低的总体延迟。
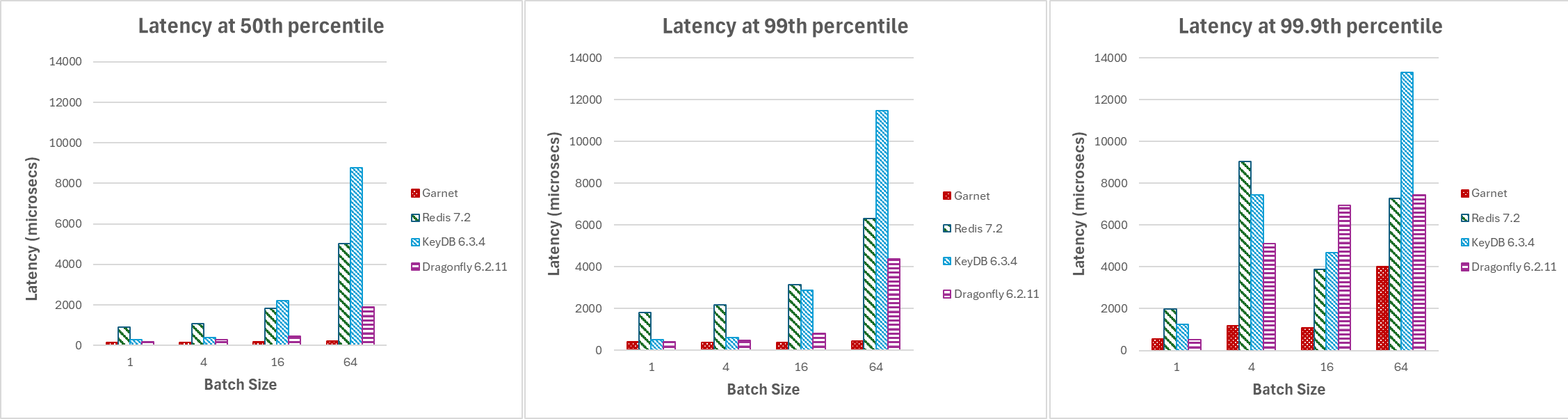 |
|---|
| 图 4:延迟,批量大小变化,在 (a) 中位数,(b) 99 百分位数,和 (c) 99.9 百分位数 |
复杂数据结构性能
Garnet 支持大量不同的复杂数据结构,例如 Hyperloglog、Bitmap、Sorted Sets、Lists 等。下面,我们介绍其中精选的几个的性能指标。
Hyperloglog
Garnet 支持其内置的 Hyperloglog (HLL) 数据结构。它使用 C# 实现,支持更新 (PFADD)、计算估计值 (PFCOUNT) 和合并 (PFMERGE) 两个或更多不同 HLL 结构等操作。HLL 数据结构通常在内存占用方面进行优化。我们的实现也不例外,当非零计数较低时使用稀疏表示,当超过给定固定阈值时使用密集表示,此时内存节省和解压缩所需的额外工作之间的权衡不再具有吸引力。在 Garnet 等并发系统中,实现 HyperLogLog (HLL) 结构的高效更新至关重要。因此,我们的实验特别关注 PFADD 的性能,并特意设计用于在以下场景下对我们的系统进行压力测试
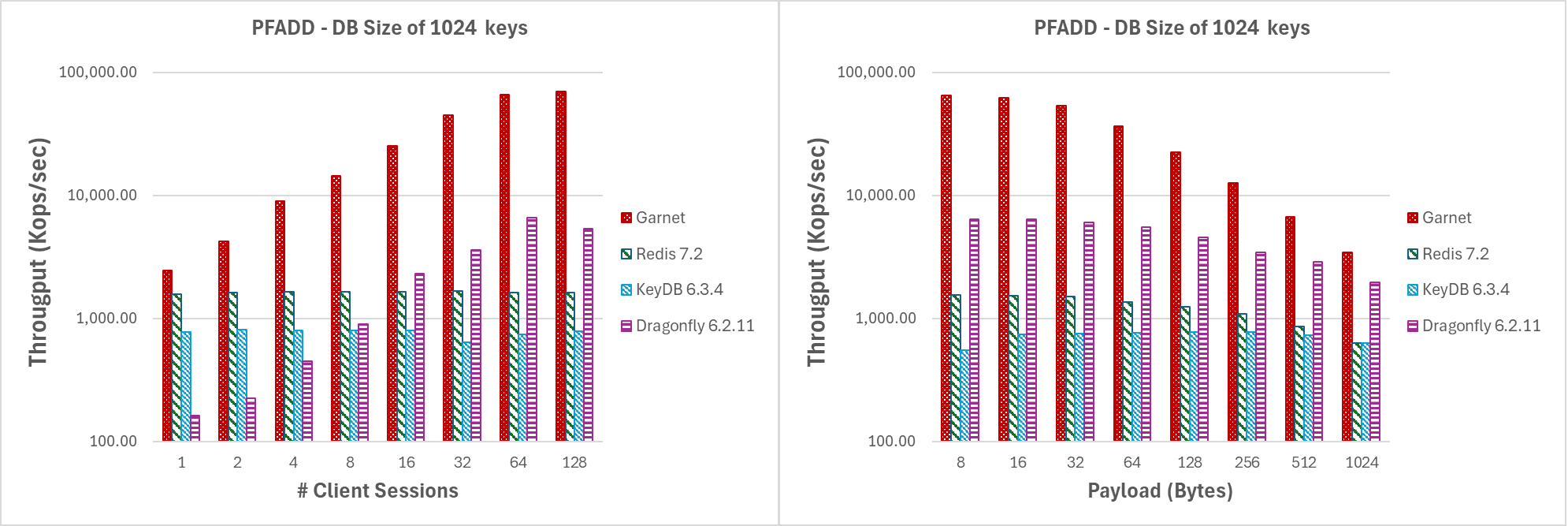
- 大量高争用更新(即批量大小 4096,数据库 1024 个键),用于增加线程数或增加有效载荷大小。经过几次插入后,构建的 HyperLogLog (HLL) 结构将转换为使用密集表示。
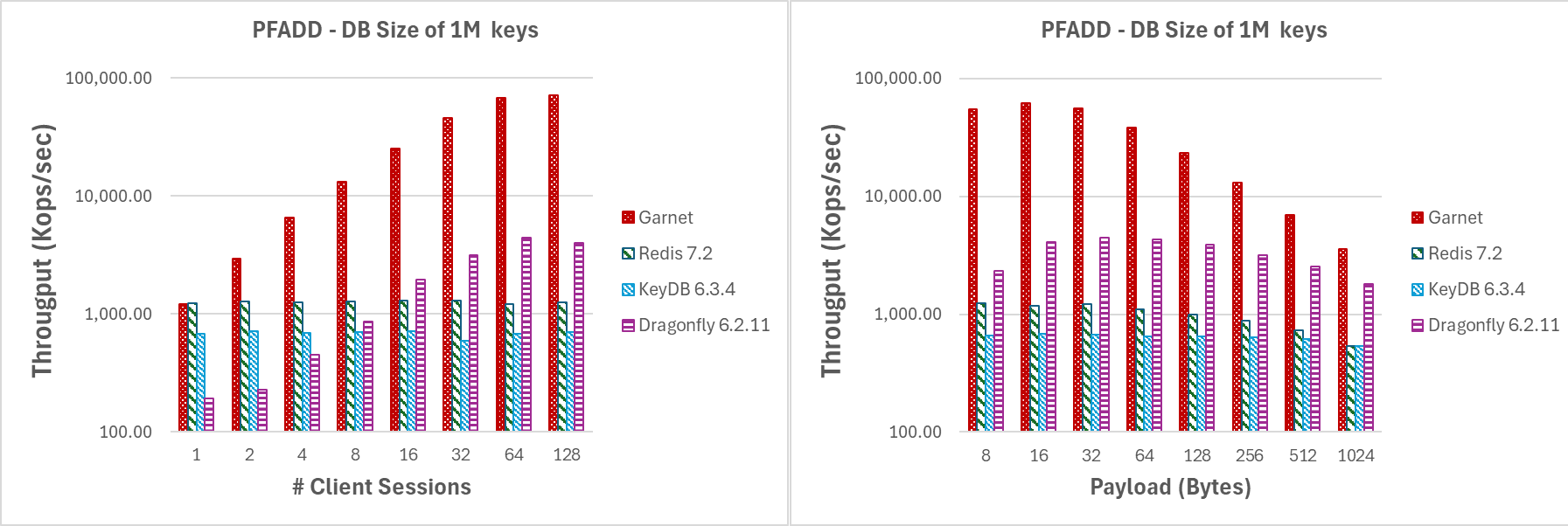
- 大量低争用更新(即批量大小 4096,数据库 2.56 亿个键),用于增加线程数或增加有效载荷大小。此调整将增加构建的 HyperLogLog (HLL) 结构使用稀疏表示的可能性。因此,我们的测量将考虑处理压缩数据或为非零值增量分配更多空间的额外开销。
在图 5 中,我们展示了第一个实验场景的结果。Garnet 在高争用下扩展性非常好,并且随着线程数量的增加,在原始吞吐量方面始终优于其他所有系统。同样,对于增加有效载荷大小,Garnet 表现出比其他系统更高的总吞吐量。在所有测试系统中,我们注意到随着有效载荷大小的增加,吞吐量显着下降。由于固有的 TCP 网络瓶颈,这种行为是预期的。
在少量键上操作时,改变客户端会话数或有效载荷大小
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op PFADD \
--keylength 8 \
--valuelength $valuelength \
--threads 1,2,4,8,16,32,64,128 \
--batchsize 4096 \
--dbsize 1024 \
--skipload
 |
|---|
| 图 5:吞吐量(对数刻度),对于 (a) 增加客户端会话数,和 (b) 增加有效载荷大小,数据库大小为 1024 个键。 |
图 6 显示了如上所述的第二个实验场景的结果。即使在 HLL 稀疏表示上操作,Garnet 也比其他任何系统表现更好,并且在增加客户端会话数时实现持续更高的吞吐量并具有很好的扩展性。同样,对于增加有效载荷大小,Garnet 通过获得更高的总体吞吐量而超越竞争对手。请注意,在这两种情况下,由于操作压缩数据的开销,吞吐量都低于之前的实验。
在大量键上操作时,改变客户端会话数或有效载荷大小 (PFADD)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op PFADD \
--keylength 8 \
--valuelength $valuelength \
--threads 1,2,4,8,16,32,64,128 \
--batchsize 4096 \
--dbsize 1048576 \
--totalops 1048576 \
--skipload
 |
|---|
| 图 6:吞吐量(对数刻度),对于 (a) 增加客户端会话数,和 (b) 增加有效载荷大小,数据库大小为 1M 个键。 |
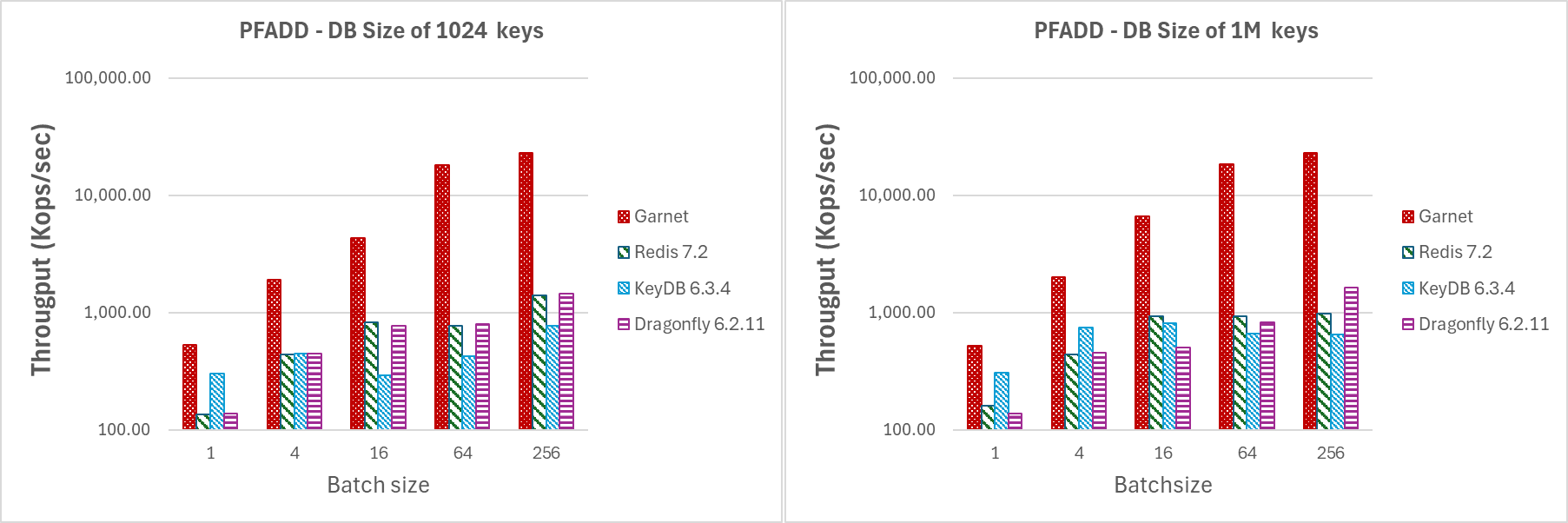
在图 7 中,我们执行与之前相同的实验类型,将客户端会话数固定为 64,有效载荷固定为 128 字节,同时增加批量大小。请注意,即使批量大小为 4,Garnet 的吞吐量增益也明显高于我们测试的任何其他系统。这表明即使批量较小,我们仍然超越竞争系统。
 |
|---|
| 图 7:吞吐量(对数刻度),对于在具有 (a) 1024 个键,(b) 1M 个键的数据库上增加 64 个客户端会话的批量大小。 |
位图
Garnet 支持对字符串数据类型进行一组面向位的操作。这些操作可以以恒定时间(即 GETBIT、SETBIT)或线性时间(即 BITCOUNT、BITPOS、BITOP)处理。为了加快处理速度,对于线性时间操作符,我们使用了硬件和 SIMD 指令。下面我们展示了这些操作符子集的基准测试结果,涵盖了两种复杂性类别。与之前类似,我们使用小数据库大小(1024 个键)来评估每个系统在高争用下的性能,同时通过增加有效载荷大小 (1MB) 来避免所有数据都驻留在 CPU 缓存中。
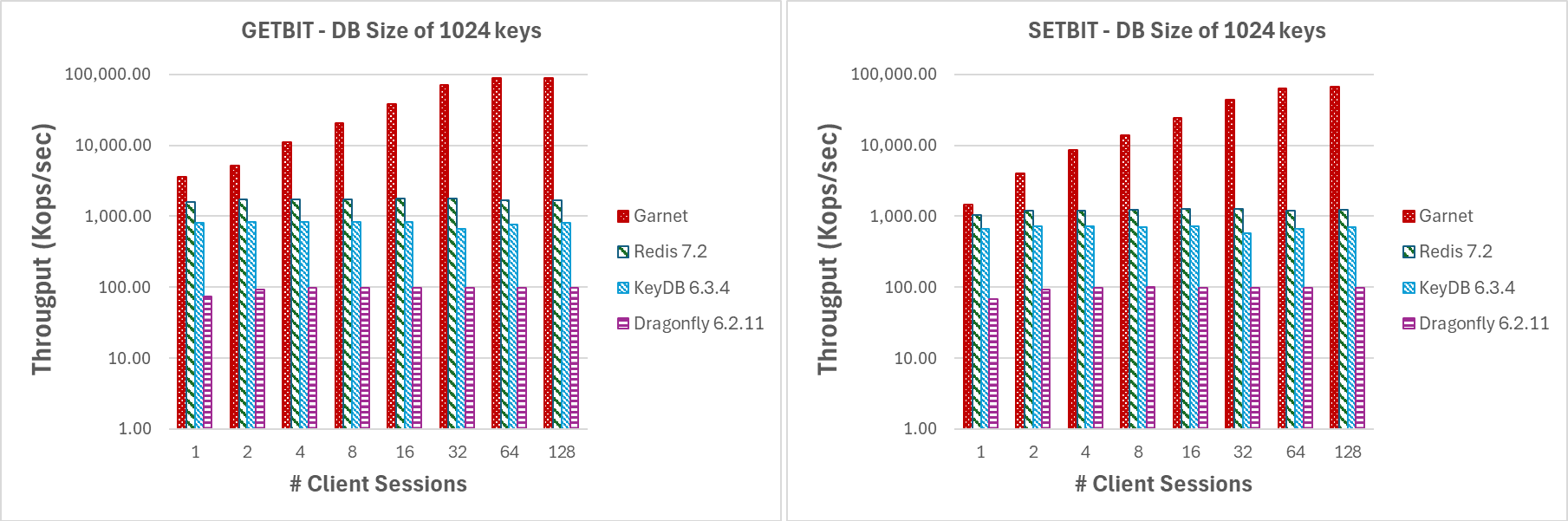
在图 8 中,我们展示了 GETBIT 和 SETBIT 命令的性能指标。在这两种情况下,随着客户端会话数量的增加,Garnet 始终保持更高的吞吐量和更好的可扩展性。
改变客户端会话数 (GETBIT/SETBIT/BITOP_NOT/BITOP_AND)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op GETBIT \
--keylength 8 \
--valuelength 1048576 \
--threads 1,2,4,8,16,32,64,128 \
--batchsize 4096 \
--dbsize 1024
 |
|---|
| 图 8:吞吐量(对数刻度),客户端会话数量变化,数据库大小为 1024 个键和 1MB 有效载荷。 |
在图 9 中,我们评估了 BITOP NOT 和 BITOP AND(带有两个源键)的性能,线程数量不断增加,有效载荷大小为 1MB。与我们测试过的所有其他系统相比,Garnet 随着客户端会话数量的增加,始终保持更高的总体吞吐量。鉴于我们的数据库大小相对较小(即只有 1024 个键),它在高争用下也表现出色。
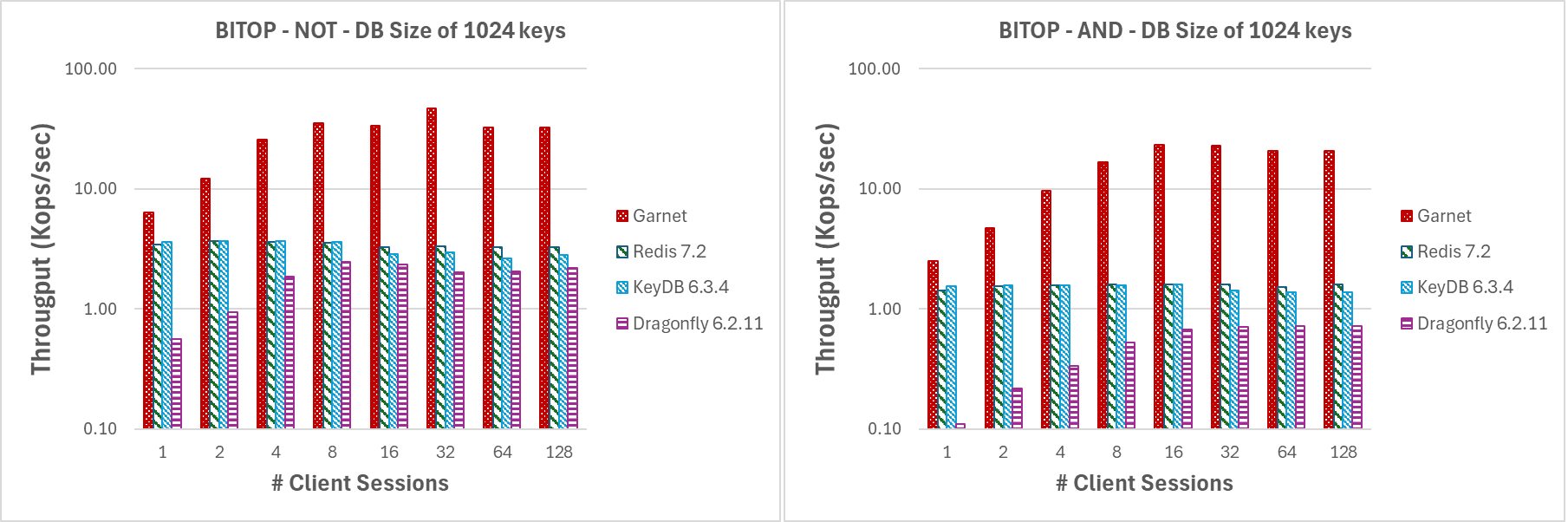 |
|---|
| 图 9:吞吐量(对数刻度),客户端会话数量变化,数据库大小为 1024 个键和 1MB 有效载荷。 |
如图 10 和图 11 所示,即使批量较小,Garnet 在相关的位图操作上也能达到比我们测试过的任何其他系统更高的吞吐量。事实上,即使批量大小为 4,我们也观察到 Garnet 的吞吐量明显更高。
改变批量大小 (GETBIT/SETBIT/BITOP_NOT/BITOP_AND)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op GETBIT \
--keylength 8 \
--valuelength 1048576 \
--threads 64 \
--batchsize $batchsize \
--dbsize 1024
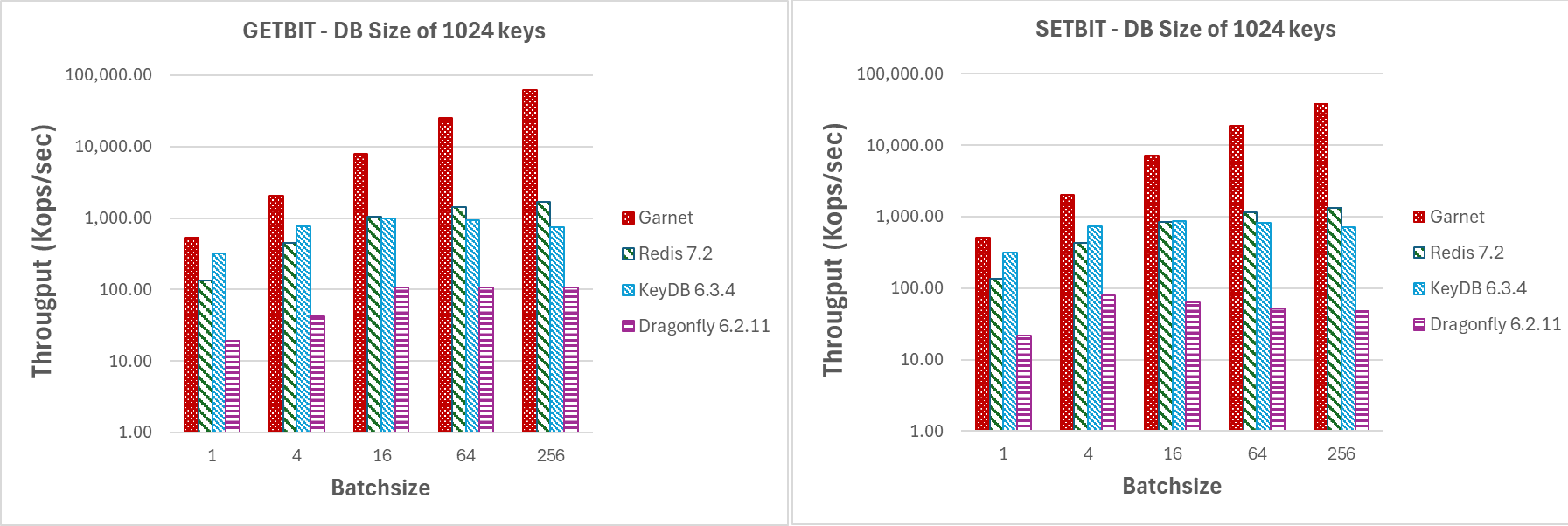 |
|---|
| 图 10:吞吐量(对数刻度),对于在具有 1024 个键和 1MB 有效载荷的数据库上增加 64 个客户端会话的批量大小。 |
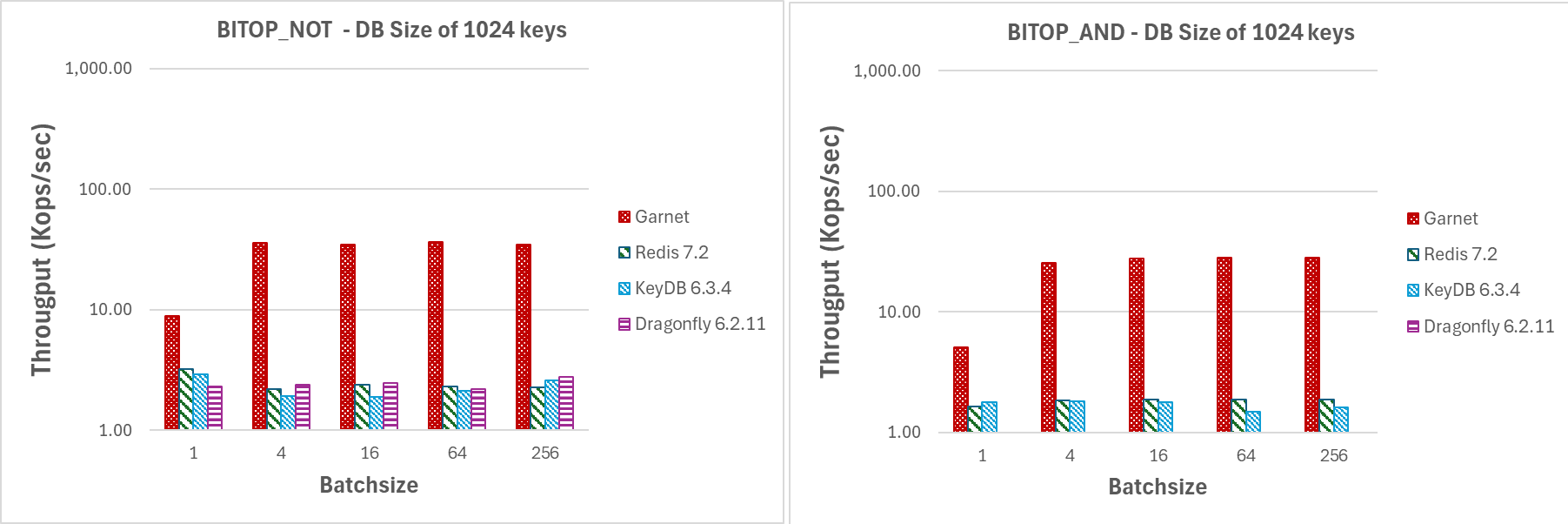 |
|---|
| 图 11:吞吐量(对数刻度),对于在具有 1024 个键和 1MB 有效载荷的数据库上增加 64 个客户端会话的批量大小。 |