对象检测
常见问题
本文试图回答与目标检测相关的常见问题。对于通用的机器学习问题,例如“我需要多少训练样本?”或“如何在训练期间监控 GPU 使用情况?”,请参阅图像分类 FAQ。
- 通用
- 数据
- 技术
- 训练
通用
为什么选择 Torchvision?
Torchvision 拥有庞大且活跃的用户群,因此其目标检测实现易于使用,经过良好测试,并采用了在社区中得到验证的最新技术。由于这些原因,我们决定使用 Torchvision 作为我们的目标检测库。对于希望尝试最新前沿技术的高级用户,我们建议从我们的 Torchvision 笔记本开始,然后也研究更具研究性质的实现,例如 mmdetection 存储库。
数据
如何标注图像?
训练和评估目标检测器需要标注目标位置。Windows 和 Linux 上最好的开源 UI 之一是 VOTT。另一个不错的工具是 LabelImg。
VOTT 可用于在图像中手动绘制一个或多个对象周围的矩形。然后,这些标注可以导出为 Pascal-VOC 格式(每个图像一个 xml 文件),提供的笔记本知道如何读取这种格式。
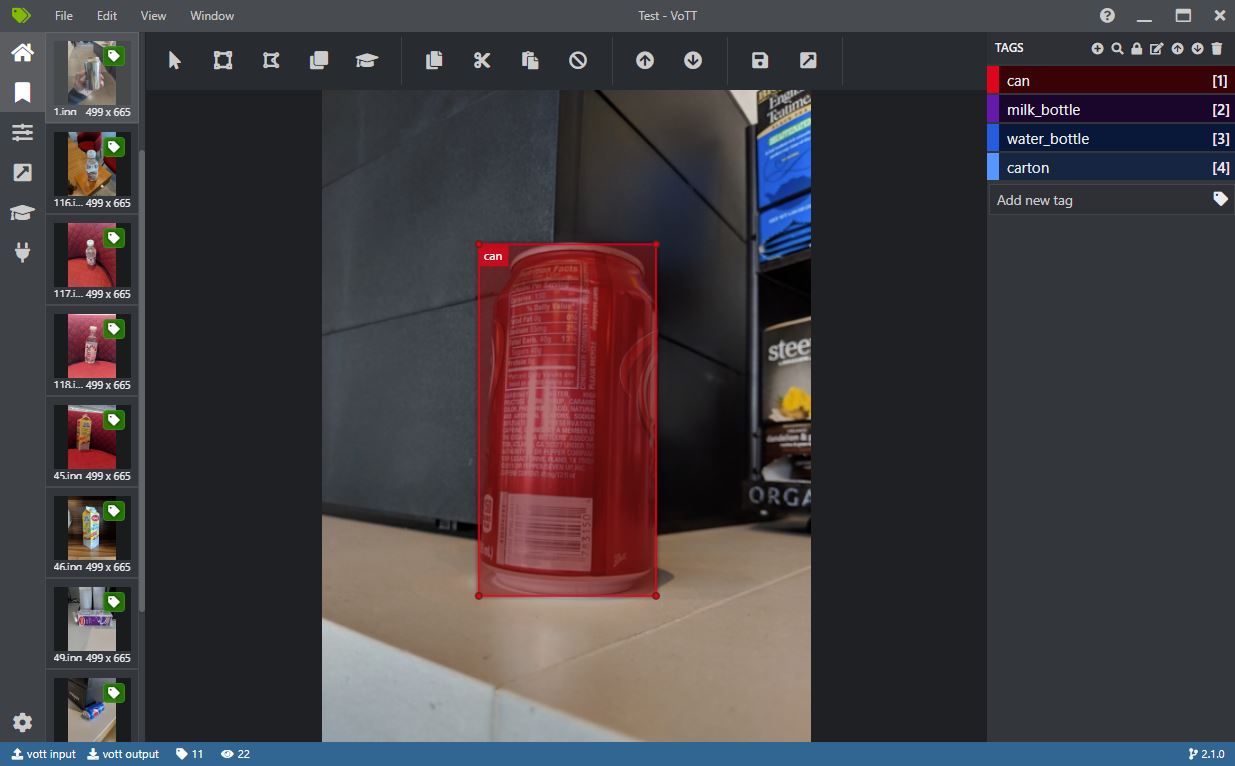
在 VOTT 中创建新项目时,请注意“源连接”可以简单地指向包含要标注图像的本地文件夹,而“目标连接”则指向写入输出的文件夹。通过在“导出设置”选项卡中选择“Pascal VOC”,然后使用“标签编辑器”选项卡中的“导出项目”按钮,可以导出 Pascal VOC 样式的标注。
对于掩码(分割)标注,一个易于使用的在线工具是 Labelbox,如下图所示。请参阅演示 Labelbox 中的图像分割简介,了解如何使用该工具,以及 02_mask_rcnn 笔记本,了解如何将 Labelbox 标注转换为 Pascal VOC 格式。Labelbox 的替代品包括 CVAT 或 RectLabel(仅限 Mac)。
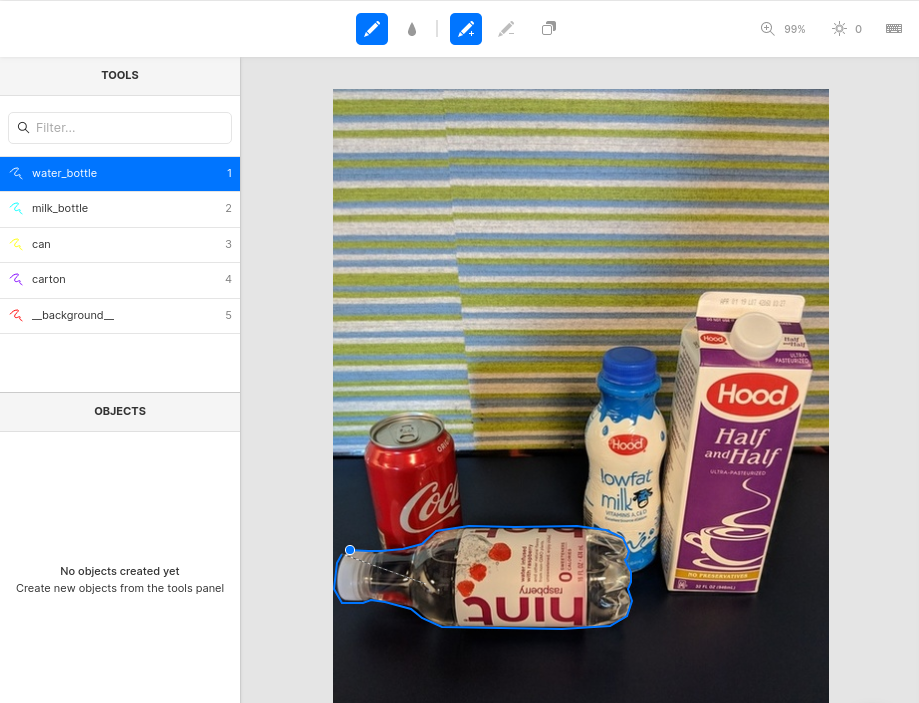
除了绘制掩码,Labelbox 还可以用于标注关键点。
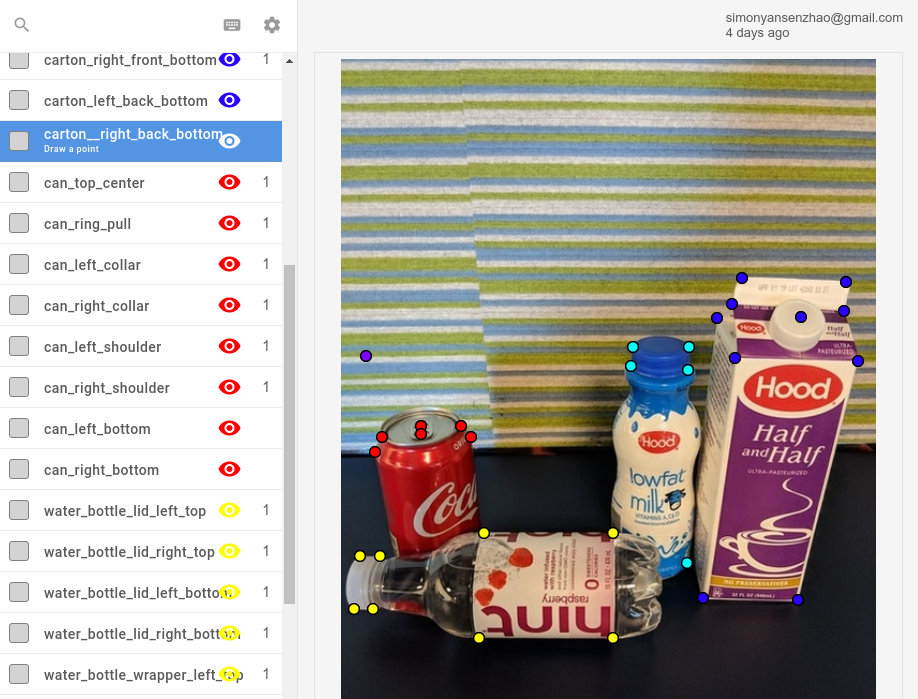
图像的选择和标注很复杂,一致性是关键。例如:
- 图像中的所有对象都需要被标注,即使图像中包含许多对象。如果这会花费太多时间,请考虑删除该图像。
- 应该删除模糊不清的图像,例如,如果人类不清楚一个物体是柠檬还是网球,或者图像模糊不清等。
- 被遮挡的物体应该始终被标注,或者从不被标注。
- 确保一致性很困难,尤其是当涉及多个人时。因此,我们的建议是,如果可能,由训练模型的人员标注所有图像。这也有助于更好地理解问题领域。
特别是用于评估的测试集应具有高质量的标注,以便准确性度量能够反映模型的真实性能。训练集可以,但理想情况下不应该,存在噪声。
技术
这项技术是如何工作的?
本存储库中使用的最新目标检测方法基于卷积神经网络(CNN),它们已被证明在图像数据上表现良好。大多数此类方法使用在数百万张图像(通常使用 ImageNet 数据集)上预训练的 CNN 作为主干。然后,将这种预训练模型整合到目标检测流水线中,并且只需要少量带标注的图像即可进行微调。有关“微调”的更详细解释,包括代码示例,请参阅 分类 文件夹。
R-CNN 目标检测方法
R-CNN 目标检测方法由 Ross Girshick 等人于 2014 年提出,并被证明在主要的物体识别挑战之一:Pascal VOC 上超越了之前最先进的方法。该方法的主要缺点是推理速度慢。自那时起,发表了三篇主要的后续论文,引入了显著的速度改进:Fast R-CNN 和 Faster R-CNN,以及 Mask R-CNN。
与大多数目标检测方法类似,R-CNN 使用经过数百万张带标注图像训练的深度神经网络进行图像分类,并将其修改用于目标检测。第一篇 R-CNN 论文的基本思想如下图所示(取自论文):
- 给定输入图像
- 生成大量区域提议,又称感兴趣区域(ROI)。
- 然后,这些 ROI 独立地通过网络,网络输出每个 ROI 的一个向量,例如 4096 个浮点值。
- 最后,学习一个分类器,它将 4096 个浮点 ROI 表示作为输入,并为每个 ROI 输出一个标签和置信度。
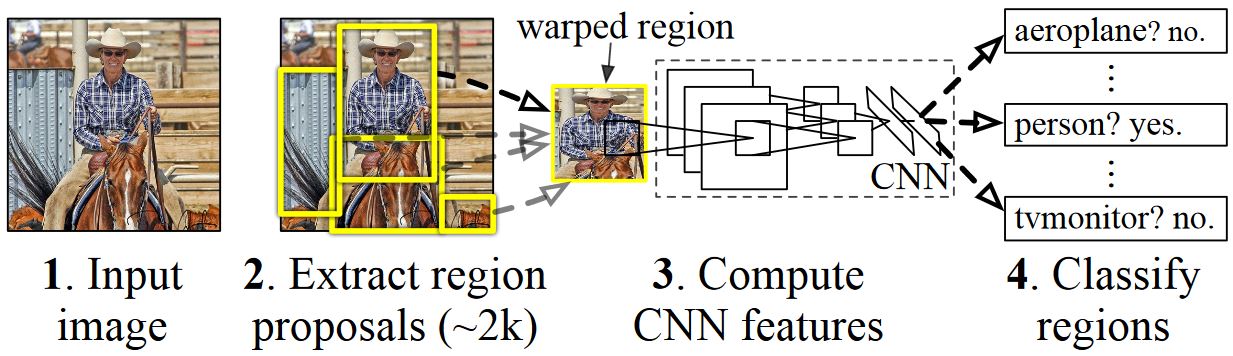
虽然这种方法在准确性方面表现良好,但由于神经网络必须为每个 ROI 进行评估,因此计算成本非常高。Fast R-CNN 通过仅对网络的大部分(具体来说:卷积层)对每个图像只评估一次来解决这个缺点。根据作者的说法,这在测试期间带来了 213 倍的速度提升,在训练期间带来了 9 倍的速度提升,而没有损失准确性。Faster R-CNN 则展示了如何将 ROI 作为网络的一部分进行计算,实质上将上图中的所有步骤组合成一个单一的 DNN。
交并比(Intersection-over-Union)重叠度量
通常需要测量两个给定矩形重叠的程度。例如,一个矩形可能对应于对象的真实位置,而第二个矩形对应于估计位置,目标是测量检测对象的精确程度。
为此,通常使用一种称为交并比(IoU)的度量。在下面的示例中,IoU 是通过将黄色区域除以黄色和蓝色区域的总和得到的。IoU 为 1.0 表示完美匹配,而 IoU 为 0 表示两个矩形不重叠。通常,IoU 为 0.5 被认为是良好的定位。另请参阅此 页面,以获取更深入的讨论。

非极大值抑制
目标检测方法通常会输出多个检测结果,这些结果完全或部分覆盖图像中的同一对象。需要对这些检测结果进行修剪,以便能够计算对象并获取其精确位置。这传统上是使用一种称为非极大值抑制(NMS)的技术完成的,其实现方法是迭代地选择置信度最高的检测结果,并移除所有其他满足以下条件的检测结果:(i) 被分类为同一类别;(ii) 使用交并比(IOU)度量具有显著重叠。
使用 IOU 阈值分别为(中)0.8 和(右)0.5 进行非极大值抑制前后(左)的带有置信度分数的检测结果

平均精度均值
训练完成后,可以使用不同的标准来衡量模型的质量,例如精确率、召回率、准确率、曲线下面积等。Pascal VOC 目标识别挑战中常用的一个指标是衡量每个类别的平均精度(AP)。平均精度考虑了检测结果的置信度,因此对低置信度的错误检测的惩罚较小。有关平均精度的描述,请参阅 Everingham 等人。然后,通过对所有 AP 取平均值来计算平均精度均值(mAP)。
训练
如何提高准确性?
提高准确性的一种方法是优化模型架构或训练过程。以下参数对准确性影响最大:
- 图像分辨率:通过设置
IM_SIZE = 1200,将输入分辨率提高到例如 1200 像素。 - 提议数量:增加到例如这些值:
rpn_pre_nms_top_n_train = rpn_post_nms_top_n_train = 10000和rpn_pre_nms_top_n_test = rpn_post_nms_top_n_test = 5000。 - 学习率和 epoch 数量:例如在 01 笔记本中指定的相应默认值在大多数情况下应该能很好地工作。但是,可以尝试稍高/稍低的学习率和 epoch 值。
有关提高模型准确性或增加推理/训练速度的更多建议,请参阅 图像分类 FAQ。