图像分类
常见问题
- 通用
- 数据
- 训练
- 故障排除
通用
这项技术是如何工作的?
最先进的图像分类方法,例如本存储库中使用的方法,基于卷积神经网络 (CNN),这是一类特殊的深度学习 (DL) 方法,已被证明在图像数据上表现良好。
CNN 的一个优点是能够通过使用少量数据集进行微调来重用在数百万张图像(通常使用 ImageNet 数据集)上训练的 CNN,以创建自定义 CNN。迁移学习方法在准确性、易于实现和通常的推理速度方面,轻松超越了“传统”(非 DL)方法。这种方法从 AlexNet 论文开始,从根本上改变了计算机视觉系统的设计。鉴于迁移学习的成功,构建 CV 解决方案中最耗时的部分现在是收集和标注数据。
AlexNet DNN 架构(如下所示)由 8 层组成:5 个卷积层,后跟 3 个全连接层。早期层学习低级特征(例如线条或边缘),这些特征在后续层中组合成越来越复杂的概念(例如车轮或面部)。ResNet 等更新的架构比 AlexNet 更深,可以包含数百个层,使用更先进的技术来帮助模型收敛。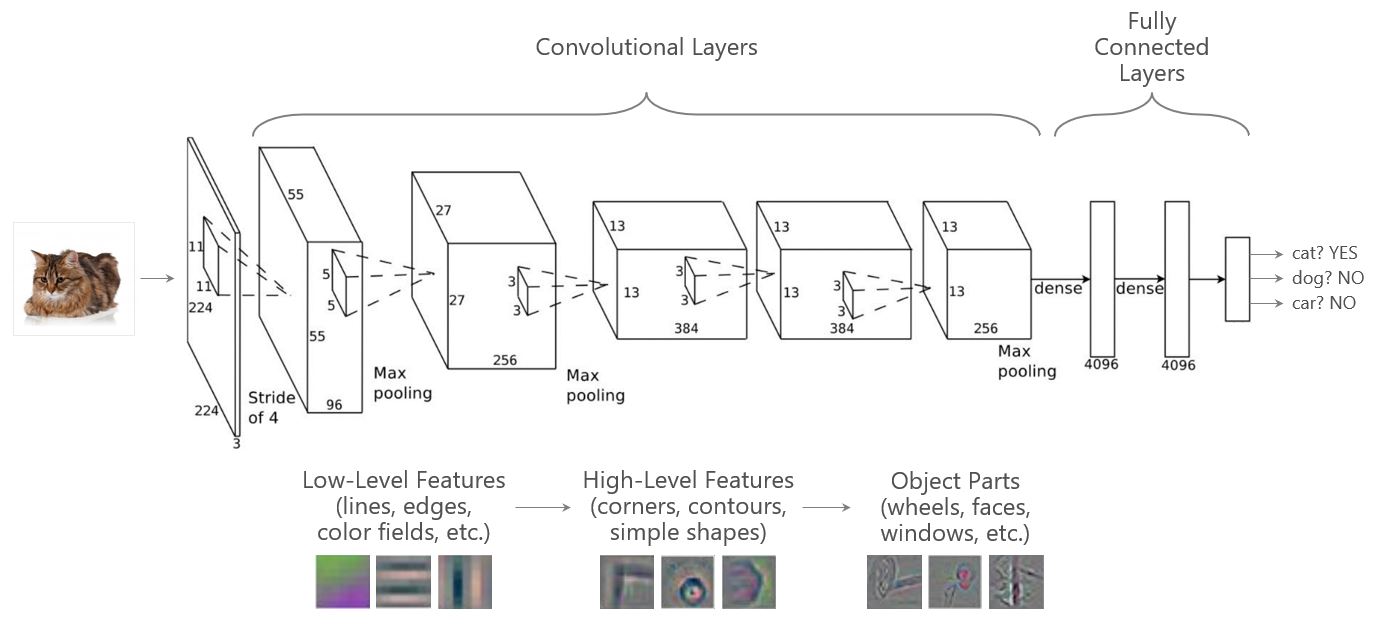
迁移学习是当前解决 CV 问题的最先进方法。为了开始了解这些概念,我们建议以下参考资料
图像分类可以解决哪些问题?
如果图像中感兴趣的对象相对较大(超过图像宽度/高度的 20%),则可以使用图像分类。如果对象较小,或者需要对象的位置,则应使用对象检测方法。
数据
训练模型需要多少张图像?
这在很大程度上取决于问题的复杂性。例如,如果感兴趣的对象在图像之间看起来非常不同(视角、光照条件等),则模型需要更多的训练图像来学习对象的出现。
我们已经看到,对于每个类别使用约 100 张图像取得了良好的结果。找到所需训练集大小的最佳方法是使用少量图像训练模型,然后逐渐增加数量,并观察模型在固定测试集上的准确性改进。一旦准确性改进停止变化(收敛),更多的训练图像将不会提高准确性,并且不是必需的。
如何收集大量的图像?
收集足够数量的用于训练和测试的带注释(标记)图像可能很困难。对于某些问题,可以从互联网上抓取额外的图像。例如,我们使用 Bing 图像搜索结果查询“条纹 T 恤”。正如预期的那样,大多数图像都与条纹 T 恤的查询匹配,少数不正确的图像很容易识别和删除。
| 必应图像搜索 | 认知服务图像搜索 |
|---|---|
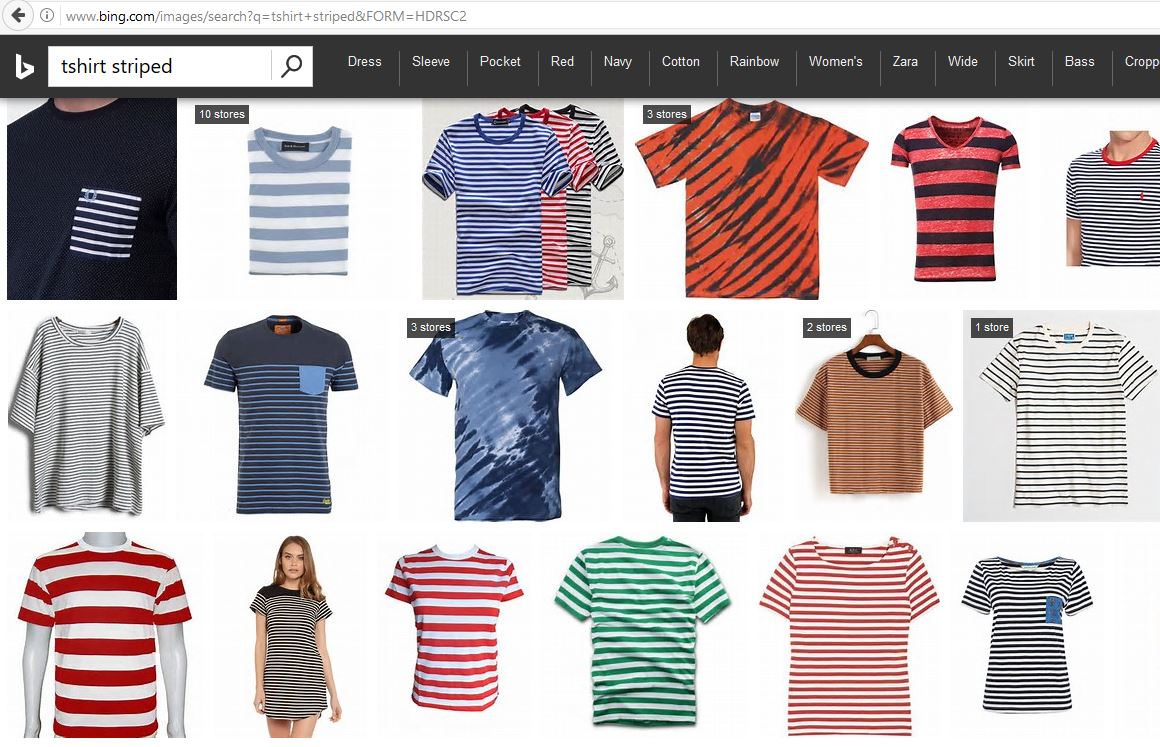 |
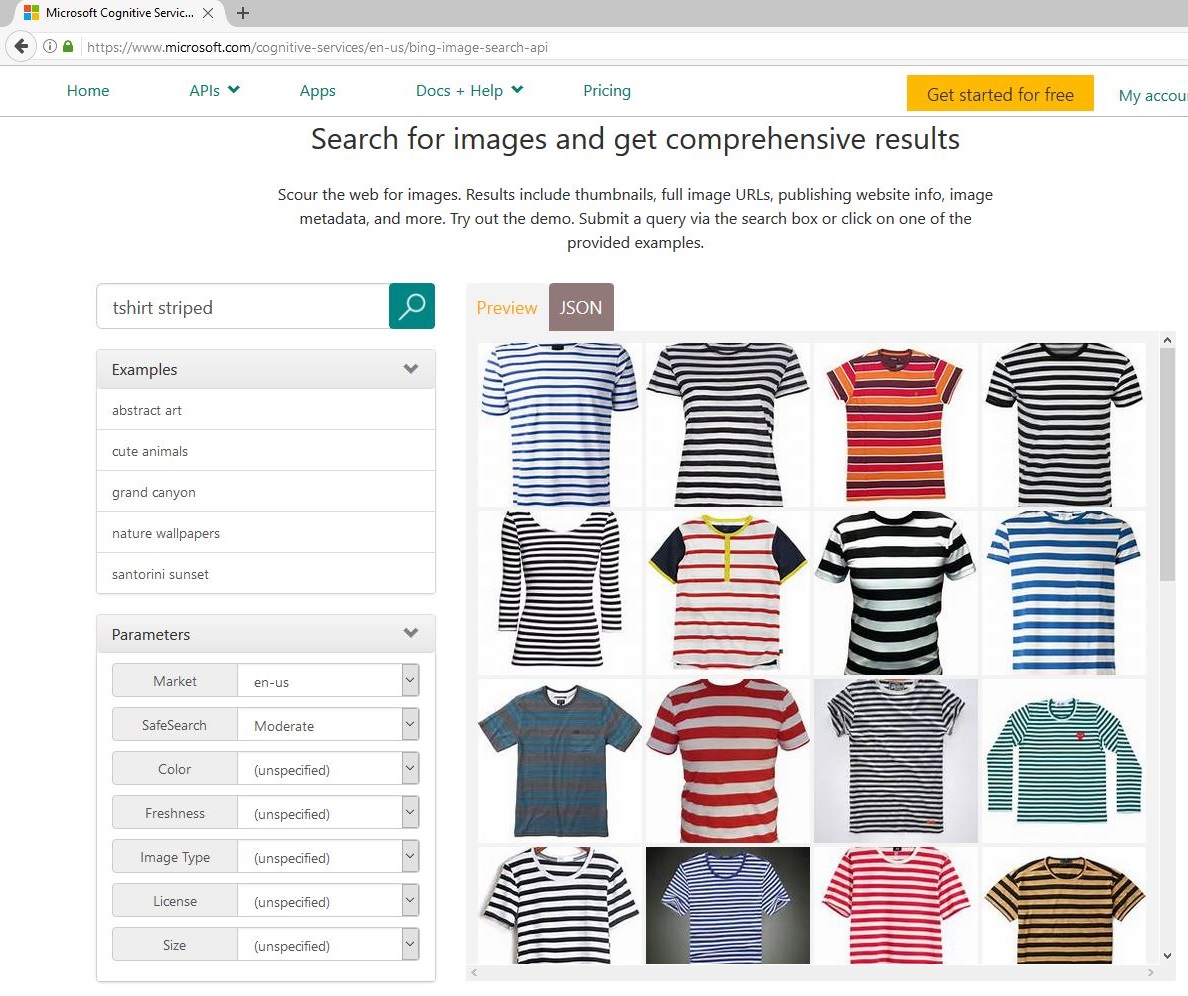 |
作为手动下载图像的替代方案,认知服务必应图像搜索 API(右图)也可用于此过程。为了使用认知服务生成一个大型且多样化的数据集,可以使用多个查询。例如,7*3 = 21 个查询可以通过 7 种服装项目 {blouse, hoodie, pullover, sweater, shirt, t-shirt, vest} 和 3 种属性 {striped, dotted, leopard} 的所有组合来合成。下载每个查询的前 50 张图像,最多可得到 21*50=1050 张图像。
自动增强训练集的一个警告是,某些下载的图像可能是完全相同或几乎重复的(因图像分辨率或 jpg 失真而异)。应删除这些图像,以使训练集和测试集不包含相同的示例图像。基于哈希的两步方法可以提供帮助:
- 为所有图像计算一个哈希字符串。
- 只保留具有唯一哈希字符串的图像。
我们发现来自 imagehash Python 库的 dhash 方法(博客),其 hash_size 参数设置为 16,非常有用。
如何增强图像数据?
使用更多的训练数据可以使模型更好地泛化,但数据收集非常昂贵。在这种情况下,通过微小修改来增强训练数据已被证明效果良好。这种方法可以避免您收集更多数据,并防止 CV 模型过拟合。
该方法使用图像变换(例如旋转、裁剪和调整亮度/对比度)来增强训练数据。这些不一定适用于所有问题,但如果转换后的图像能够代表将应用 CV 模型的整体图像总体,则可能会有所帮助。例如,在下图中,水平和垂直翻转会损害字符识别中的模型性能,因为这些方向对模型结果具有信息性。然而,在瓶子图像示例中,垂直翻转可能不会提高模型准确性,但水平翻转可能会。这两个方向在卫星图像问题中都有帮助。
 不同图像变换的示例(第一行:MNIST,第二行:冰箱物体,第三行:Planet)
不同图像变换的示例(第一行:MNIST,第二行:冰箱物体,第三行:Planet)
如何标注图像?
标注图像既复杂又昂贵。一致性是关键。被遮挡的物体应该始终被标注,或者从不标注。模棱两可的图像应该被移除,例如,如果人类不清楚图像显示的是柠檬还是网球。确保一致性很困难,尤其是当有多人参与时,因此我们的建议是只由一个人标注所有图像。如果该人也训练 AI 模型,那么标注过程有助于更好地理解图像和分类任务的复杂性。
请注意,测试集应具有高质量的标注,以确保模型准确性估计可靠。
如何将图像分割成训练集和测试集?
通常随机分割就可以了,但也有例外。例如,如果图像是从电影中提取的,那么训练集中有帧 n,测试集中有帧 n+1 将导致准确性估计过高,因为这两个图像太相似。此外,如果数据中存在固有的类别不平衡,则应该有其他控制措施来确保所有类别都包含在训练和测试数据集中。
如何设计一个好的测试集?
测试集应包含与模型将用于评分的总体相似的图像。例如,在相似光照条件、相似角度等下拍摄的图像。这有助于确保准确性估计反映使用训练模型的应用程序的真实性能。
训练
如何加速训练?
- 所有图像都可以存储在本地 SSD 设备上,因为 HDD 或网络访问时间可能会主导训练时间。
- 高分辨率图像会由于 JPEG 解码成为瓶颈而减慢训练速度(>10 倍的性能损失)。有关更多信息,请参阅 02_training_accuracy_vs_speed.ipynb 笔记本。
- 非常高分辨率的图像(>4 兆像素)可以在 DNN 训练之前缩小尺寸。
如何提高准确性或推理速度?
请参阅 02_training_accuracy_vs_speed.ipynb 笔记本,其中讨论了哪些参数很重要,以及选择针对更快推理速度优化的模型的策略。
如何在训练期间监控 GPU 使用情况?
存在用于监控实时 GPU 信息(例如 GPU 或内存负载)的各种工具。这是一份我们使用过的工具的不完整列表
- GPU-Z:具有易于安装的用户界面。
- nvidia-smi:命令行工具。预装在 Azure Data Science VM 上。
- GPU monitor:用于监控单机或集群中 GPU 的 Python SDK。
故障排除
小部件未显示
Jupyter 小部件非常不稳定,在某些系统上可能无法正确渲染,或者经常根本不显示。如果出现这种情况,请尝试
- 使用不同的浏览器
- 使用以下命令升级 Jupyter notebook 库
# Update jupyter notebook activate cv conda upgrade notebook # Run notebook server in activated 'cv' environment activate cv jupyter notebook