多目标跟踪
常见问题
本文档包含与多目标跟踪常见问题和主题相关的答案和信息。有关更一般的机器学习问题,例如“我需要多少训练样本?”或“如何在训练期间监控 GPU 使用情况?”,另请参阅图像分类 常见问题。
- 数据
- 训练和推理
- 评估
- 最先进 (SoTA) 技术
- [热门出版物和数据集]
数据
如何标注图像?
对于训练,我们使用与目标检测完全相同的标注格式(请参阅此 常见问题)。这也意味着我们从单个帧进行训练,而不考虑这些帧的时间位置。
为了进行评估,我们遵循 py-motmetrics 存储库,该存储库要求真实数据采用 MOT 挑战 格式。为了进行真实标注,默认情况下可以将最后 3 列设置为 -1
[frame number] [id number] [bbox left] [bbox top] [bbox width] [bbox height][confidence score][class][visibility]
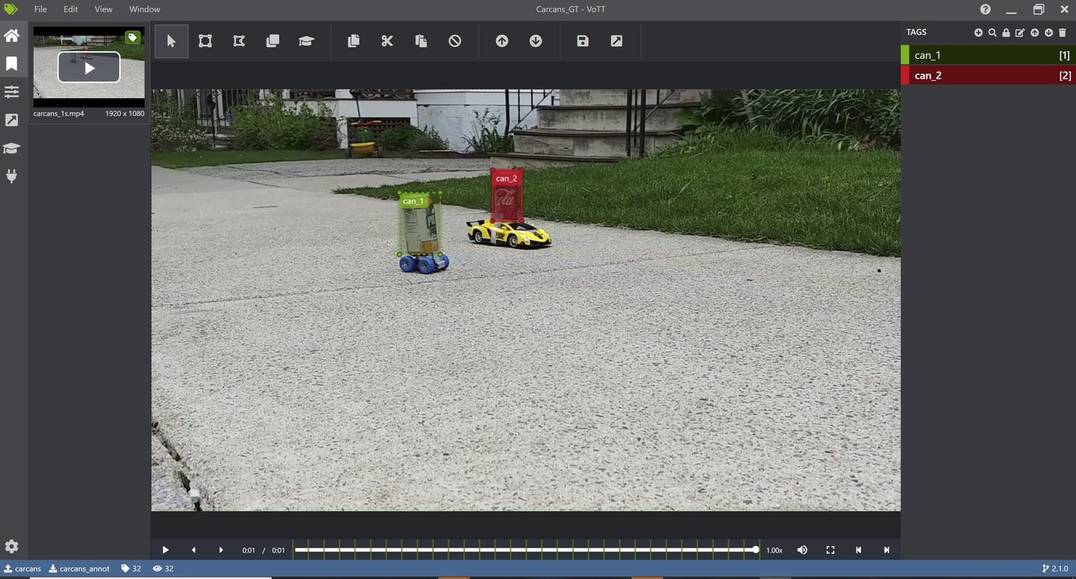
请参阅下面的示例,我们使用 VOTT 将图像中的两个罐头标注为 can_1 和 can_2,其中 can_1 指的是白色/黄色罐头,can_2 指的是红色罐头。在标注之前,务必正确设置提取速率以匹配视频的速率。标注后,您可以将标注结果导出为多种形式,例如 PASCAL VOC 或 .csv 形式。对于 .csv 格式,VOTT 将返回提取的帧,以及一个包含边界框和 ID 信息的 csv 文件
[image] [xmin] [y_min] [x_max] [y_max] [label]
在后台(不对用户公开),FairMOT 存储库使用这种标注格式进行训练,其中每行描述一个边界框,如下所述,如 Towards-Realtime-MOT 存储库中所述
[class] [identity] [x_center] [y_center] [width] [height]
class 字段全部设置为 0,因为 FairMOT 存储库目前仅支持单类多目标跟踪(例如罐头)。身份字段是 0 到 num_identities - 1 之间的整数,它将类名映射到整数(例如可乐罐、咖啡罐等)。[x_center] [y_center] [width] [height] 的值通过图像的宽度/高度进行归一化,范围从 0 到 1。
训练和推理
FairMOT 中的训练损失是什么?
FairMOT 生成的损失包括检测特定损失(例如 hm_loss、wh_loss、off_loss)和 ID 特定损失(id_loss)。总损失(loss)是检测特定损失和 ID 特定损失的加权平均值,请参阅 FairMOT 论文。
FairMOT 中的主要推理参数是什么?
- input_w 和 input_h:数据集视频帧的图像分辨率
- conf_thres、nms_thres、min_box_area:这些阈值用于根据用户要求过滤掉不符合置信度、NMS 水平或大小的检测;
- track_buffer:如果丢失的轨迹在由该阈值确定的帧数内未匹配,则将其删除,即 ID 不会重用。
评估
什么是 MOT 挑战?
MOT 挑战 网站托管了最常见的行人 MOT 基准测试数据集。存在不同的数据集:MOT15、MOT16/17、MOT 19/20。这些数据集包含许多视频序列,具有不同的跟踪难度级别和标注的真实值。还提供了检测结果供参与跟踪算法选择性使用。
常用的评估指标有哪些?
由于多目标跟踪是一项复杂的计算机视觉任务,因此存在许多不同的指标来评估跟踪性能。根据它们的计算方式,指标可以是基于事件的 CLEARMOT 指标 或 基于 ID 的指标。在 MOT 基准测试挑战 中衡量性能的主要指标包括 MOTA、IDF1 和 ID-switch。
- MOTA(多目标跟踪精度)使用基于事件的计算来衡量跟踪结果与真实值之间不匹配的频率,从而评估整体精度性能。MOTA 包含 FP(假阳性)、FN(假阴性)和 ID 切换 (IDSW) 的计数,并按真实值 (GT) 轨迹的总数进行归一化。
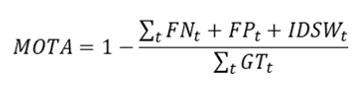
- IDF1 通过基于 ID 的计算衡量跟踪器正确识别目标的时间,从而衡量整体性能。它是识别精度 (IDP) 和召回率 (IDR) 的调和平均值。

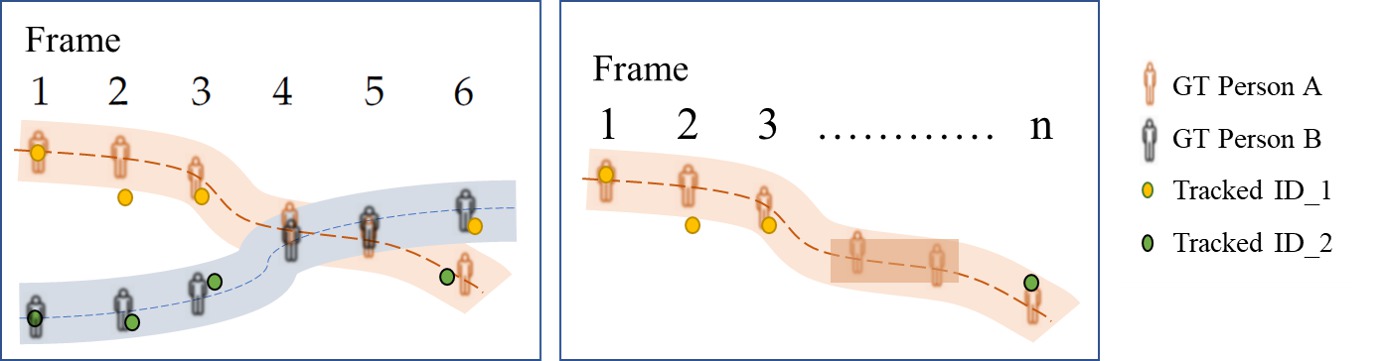
- ID-switch 衡量跟踪器错误更改轨迹 ID 的情况。这在下图中有所说明:在左侧框中,人 A 和人 B 重叠,在第 4-5 帧中未被检测和跟踪。这导致在第 6 帧中发生 ID 切换,其中人 A 被赋予 ID_2,该 ID 之前标记为人 B。在右侧框中的另一个示例中,跟踪器在第 3 帧后失去了对人 A(最初识别为 ID_1)的跟踪,并最终在第 n 帧中用新的 ID (ID_2) 识别该人,显示了另一个 ID 切换实例。
最先进
FairMOT 跟踪算法的架构是什么?
它由一个单一的编码器-解码器神经网络组成,用于提取图像帧的高分辨率特征图。作为一个一次性跟踪器,它输入两个并行头部,分别用于预测边界框和重识别特征,请参阅 来源
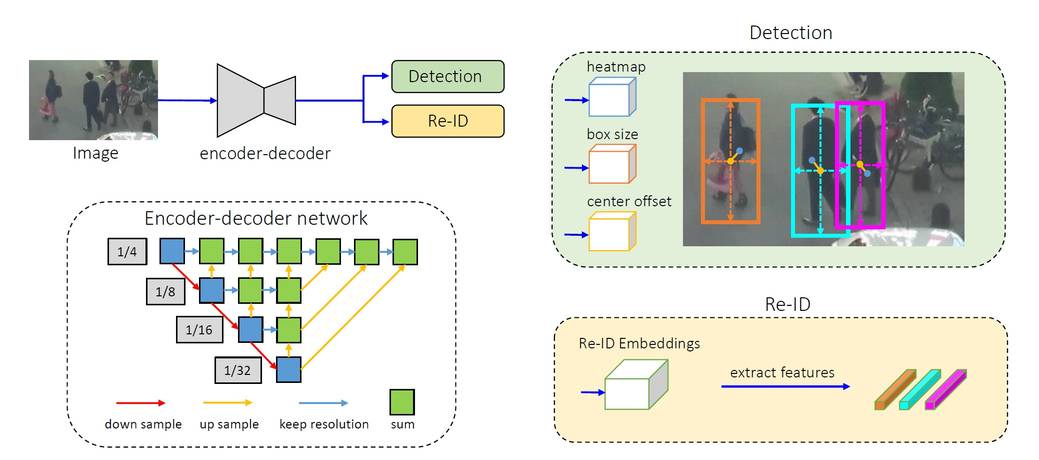
来源:[Zhang, 2020](https://arxiv.org/pdf/2004.01888v2.pdf)
基于检测的跟踪器使用哪些目标检测器?
SoTA 跟踪算法最常用的目标检测器包括:Faster R-CNN、SSD 和 YOLOv3。请参阅我们的 目标检测常见问题页面 获取更多详细信息。
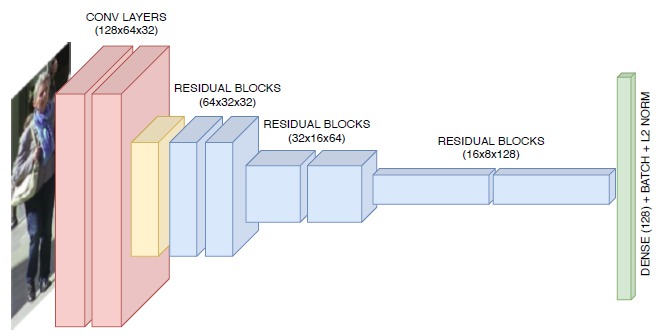
虽然较老的算法使用局部特征,例如光流或区域特征(例如颜色直方图、基于梯度的特征或协方差矩阵),但较新的算法具有基于深度学习的特征表示。最常见的基于深度学习的方法,通常在重识别数据集上训练,使用经典的 CNN 提取视觉特征。其中一个数据集是 MARS 数据集。下图是 DeepSORT 跟踪器 用于 MOT 的 CNN 示例:
较新的深度学习方法包括 Siamese CNN 网络、LSTM 网络或带有相关滤波器的 CNN。在 Siamese CNN 网络中,使用一对相同的 CNN 网络来测量两个对象之间的相似性,并且 CNN 使用学习特征以最好地区分它们的损失函数进行训练。 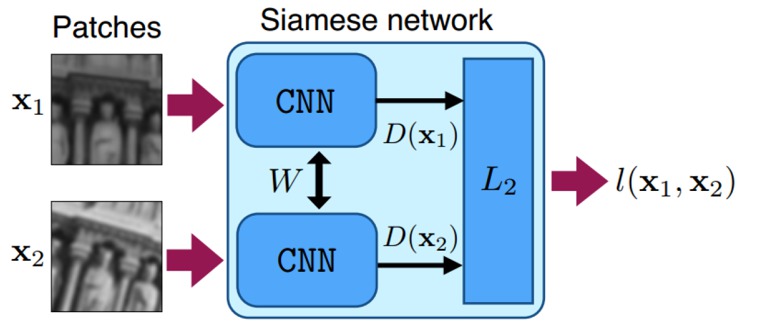
来源:[(Simon-Serra et al, 2015)](https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Simo-Serra_Discriminative_Learning_of_ICCV_2015_paper.pdf)
在 LSTM 网络中,从不同时间帧的不同检测中提取的特征用作输入。网络根据输入历史预测下一帧的边界框。
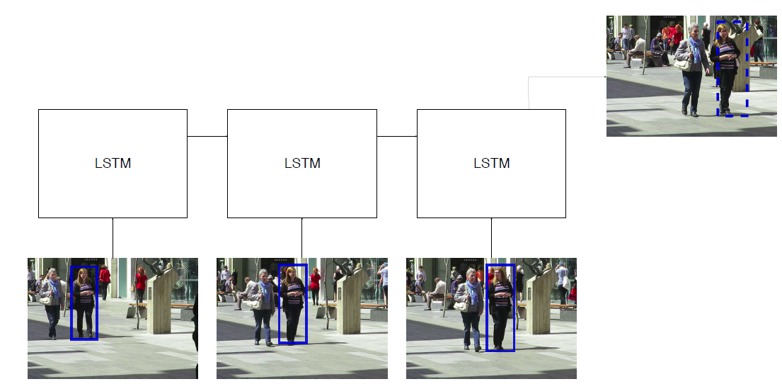
来源:[Ciaparrone, 2019](https://arxiv.org/pdf/1907.12740.pdf)
相关滤波器也可以与 CNN 网络的特征图进行卷积,以生成下一时间帧中目标位置的预测。 Ma et al 进行了如下操作:
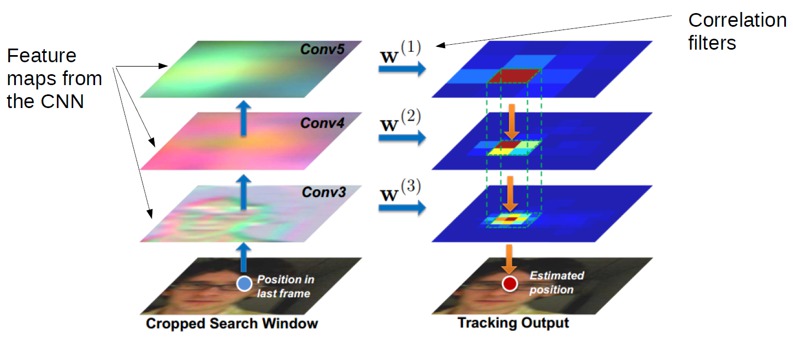
基于检测的跟踪器使用哪些亲和度和关联技术?
简单的方法使用从 CNN 提取的特征的距离度量计算出的相似度/亲和度分数,以在连续帧中最佳匹配对象检测/轨迹与已建立的对象轨迹。为此,通常使用匈牙利(Huhn-Munkres)算法进行在线数据关联,而使用 K-部图全局优化技术进行离线数据关联。
在更复杂的深度学习方法中,亲和度计算通常与特征提取合并。例如,Siamese CNN 和 Siamese LSTM 直接输出亲和度分数。
在线和离线跟踪算法有什么区别?
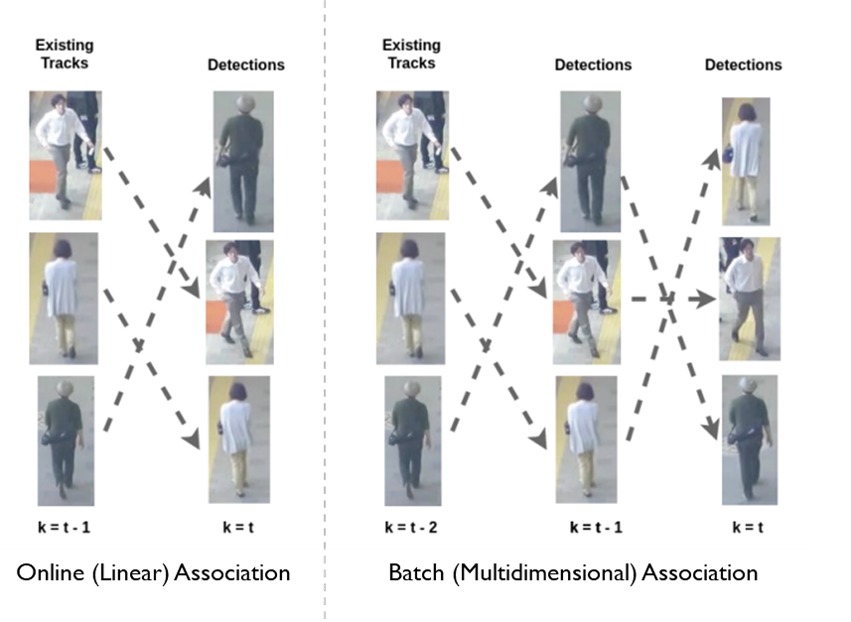
在线和离线算法在数据关联步骤上有所不同。在在线跟踪中,新帧中的检测与先前帧中生成的轨迹相关联。因此,现有轨迹得到扩展或创建新轨迹。在离线(批处理)跟踪中,可以全局考虑一批帧中的所有观测值(见下图),即通过获得全局最优解将它们链接成轨迹。离线跟踪可以更好地处理长期遮挡或空间上接近的相似目标等跟踪问题。然而,离线跟踪往往较慢,因此不适合需要实时处理的任务,例如自动驾驶。
热门出版物和数据集
热门数据集
| 名称 | 年份 | 持续时间 | 轨迹/ID 数量 | 场景 | 对象类型 | | ----- | ----- | -------- | -------------- | ----- | ---------- | | [MOT15](https://arxiv.org/pdf/1504.01942.pdf)| 2015 | 16 分钟 | 1221 | 户外 | 行人 | | [MOT16/17](https://arxiv.org/pdf/1603.00831.pdf)| 2016 | 9 分钟 | 1276 | 户外 & 室内 | 行人 & 车辆 | | [CVPR19/MOT20](https://arxiv.org/pdf/1906.04567.pdf)| 2019 | 26 分钟 | 3833 | 拥挤场景 | 行人 & 车辆 | | [PathTrack](http://openaccess.thecvf.com/content_ICCV_2017/papers/Manen_PathTrack_Fast_Trajectory_ICCV_2017_paper.pdf)| 2017 | 172 分钟 | 16287 | YouTube 人物场景 | 人员 | | [Visdrone](https://arxiv.org/pdf/1804.07437.pdf)| 2019 | - | - | 无人机摄像头户外视图 | 行人 & 车辆 | | [KITTI](http://www.jimmyren.com/papers/rrc_kitti.pdf)| 2012 | 32 分钟 | - | 汽车摄像头交通场景 | 行人 & 车辆 | | [UA-DETRAC](https://arxiv.org/pdf/1511.04136.pdf) | 2015 | 10 小时 | 8200 | 交通场景 | 车辆 | | [CamNeT](https://vcg.ece.ucr.edu/sites/g/files/rcwecm2661/files/2019-02/egpaper_final.pdf) | 2015 | 30 分钟 | 30 | 户外 & 室内 | 人员 |
热门出版物
| 名称 | 年份 | MOT16 IDF1 | MOT16 MOTA | 推理速度 (fps) | 在线/批处理 | 检测器 | 特征提取/运动模型 | 亲和度与关联方法 | | ---- | ---- | ---------- | ---------- | -------------------- | ------------- | -------- | -------------------------------- | -------------------- | |[多目标跟踪的简单基线 -FairMOT](https://arxiv.org/pdf/2004.01888.pdf)|2020|70.4|68.7|25.8|在线|带检测头的一次性跟踪器|带重识别头和多层特征聚合的一次性跟踪器,IOU,卡尔曼滤波器|基于 IOU、嵌入距离的 JV 算法| |[如何训练你的深度多目标跟踪器 -DeepMOT-Tracktor](https://arxiv.org/pdf/1906.06618v2.pdf)|2020|53.4|54.8|1.6|在线|单目标跟踪器:Faster-RCNN (Tracktor),GO-TURN,SiamRPN|Tracktor,CNN 重识别模块|使用 Bi-RNN 的深度匈牙利网络| |[没有花哨的跟踪 -Tracktor](https://arxiv.org/pdf/1903.05625.pdf)|2019|54.9|56.2|1.6|在线|修改后的 Faster-RCNN|带边界框相机运动补偿的时间边界框回归,来自 Siamese CNN 的重识别嵌入|使用重识别嵌入距离合并轨迹的贪婪启发式算法| |[实时多目标跟踪 -JDE](https://arxiv.org/pdf/1909.12605v1.pdf)|2019|55.8|64.4|18.5|在线|一次性跟踪器 - 带 FPN 的 Faster R-CNN|一次性 - 带 FPN 的 Faster R-CNN,卡尔曼滤波器|匈牙利算法| |[利用连接性:使用 TrackletNet 进行多目标跟踪 -TNT](https://arxiv.org/pdf/1811.07258.pdf)|2019|56.1|49.2|0.7|批处理|MOT 挑战检测|带边界框相机运动补偿的 CNN,嵌入特征相似度|基于 CNN 的轨迹对相似度测量;基于轨迹的图割优化| |[通过视觉信息扩展基于 IOU 的多目标跟踪 -VIOU](http://elvera.nue.tu-berlin.de/typo3/files/1547Bochinski2018.pdf)|2018|56.1(VisDrone)|40.2(VisDrone)|20(VisDrone)|批处理|Mask R-CNN,CompACT|IOU|KCF 使用贪婪 IOU 启发式算法合并轨迹| |[使用深度关联度量的简单在线实时跟踪 -DeepSORT](https://arxiv.org/pdf/1703.07402v1.pdf)|2017|62.2| 61.4|17.4|在线|修改后的 Faster R-CNN|CNN 重识别模块,IOU,卡尔曼滤波器|匈牙利算法,使用马哈拉诺比斯距离(运动)和嵌入距离的级联方法 | |[通过提升多切割和行人重识别进行多人跟踪 -LMP](http://openaccess.thecvf.com/content_cvpr_2017/papers/Tang_Multiple_People_Tracking_CVPR_2017_paper.pdf)|2017|51.3|48.8|0.5|批处理|[公共检测](https://arxiv.org/pdf/1610.06136.pdf)|StackeNetPose CNN 重识别模块|时空关系,深度匹配,重识别置信度;基于检测的图提升多切割优化|