用于动作识别的视频标注摘要
为了创建用于动作识别的训练或评估集,需要标注视频中动作的真实开始/结束位置。我们研究了各种工具,其中我们最喜欢的工具(迄今为止)是牛津大学 VGG 团队编写的 VGG 图像标注器 (VIA)。
VIA 工具使用说明
现在我们将提供一些使用 VIA 工具的技巧/步骤。该工具的完整功能实时演示可以在此处找到。
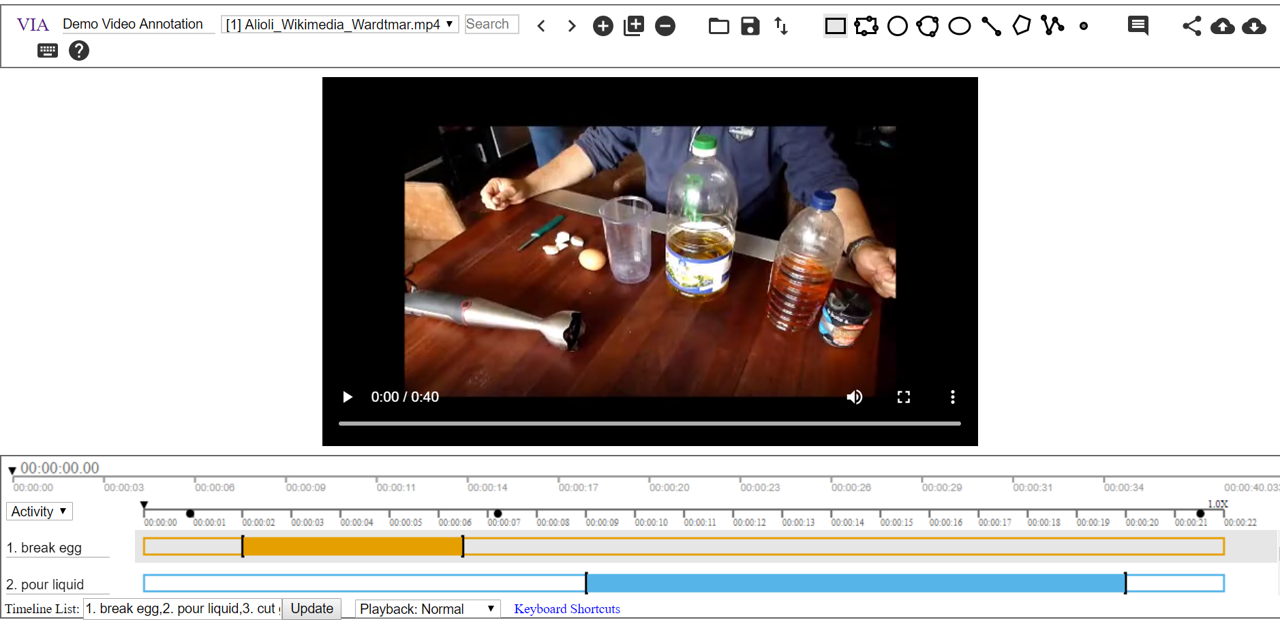
VIA 工具截图
如何使用该工具进行动作识别
- 第 1 步:从此处下载 zip 文件。
- 第 2 步:解压该工具并打开 via_video_annotator.html 以打开标注工具。注意:对某些浏览器的支持似乎不够稳定 - 我们发现 Chrome 浏览器效果最好。
- 第 3 步:使用
 从本地导入视频文件,或使用
从本地导入视频文件,或使用  从 URL 导入。
从 URL 导入。 - 第 4 步:使用
 为动作标注创建新属性。选择 Temporal Segment in Video or Audio 作为 Anchor。要查看创建的属性,请再次单击 。
为动作标注创建新属性。选择 Temporal Segment in Video or Audio 作为 Anchor。要查看创建的属性,请再次单击 。 - 第 5 步:使用您想要跟踪的动作更新 Timeline List。例如,将不同的动作通过“1. 吃,2. 喝”分开,分别用于“吃”和“喝”两个轨道。单击 update 查看更新后的轨道。
- 第 6 步:单击一个轨道以添加某个动作的片段标注。使用键
a在当前时间添加时间片段,使用Shift + a将时间片段的边缘更新到当前时间。 - 第 7 步:使用
 导出标注。如果您只有时间片段标注,请选择 Only Temporal Segments as CSV。
导出标注。如果您只有时间片段标注,请选择 Only Temporal Segments as CSV。
用于 VIA 工具的脚本
VIA 工具将标注输出为 CSV 文件。然而,我们经常需要将每个标注的动作作为其自己的片段写入单独的文件中。这些片段可以作为动作识别模型的训练示例。我们提供了一些脚本来帮助构建此类数据集。
- video_conversion.py - 将视频片段转换为 VIA 工具可以读取的格式。
- clip_extraction.py - 将每个标注的动作提取为单独的片段。可选地,可以生成不包含目标动作的“负面”片段。负面片段可以通过两种方式提取:可以提取所有连续的不重叠的负面片段,或者可以随机采样指定数量的负面示例。此行为可以通过
contiguous标志控制。该脚本将片段输出到每个类别特定的目录中,并生成一个标签文件,将每个文件名映射到该片段的类别标签。 - split_examples.py - 将生成的示例片段分割成训练集和评估集。可选地,可以生成一个负面候选集和负面测试集用于硬负面挖掘。
标注工具比较
下面是用于标注动作的替代 UI 列表,但我们认为 VIA 工具是迄今为止表现最好的。我们区分以下两种类型:
- 固定长度片段标注:UI 将视频分割成固定长度的片段,然后用户标注这些片段。
- 分割标注:用户直接标注每个动作的精确开始和结束位置。与固定长度片段标注相比,这更耗时,但具有更高的定位准确性。
另请参阅 HACS 数据集网页,了解展示这两种标注类型的一些示例。
| 工具名称 | 标注类型 | 优点 | 缺点 | 是否开源 |
|---|---|---|---|---|
| MuViLab | 固定长度片段标注 | <ul><li> 通过同时显示多个片段来加速片段标注</li> <li> 在动作稀疏时特别有用</li></ul> |
<ul><li> 当动作非常短(例如一秒)时不适用</li></ul> | Github 上开源 |
| VIA (VGG 图像标注器) | 分割标注 | <ul><li> 轻量级,除了下载 zip 文件外没有其他先决条件</li> <li> 积极开发的 Gitlab 项目 </li> <li> 支持:高精度(毫秒和帧)视频标注、预览标注片段、将动作的开始和结束时间导出为 csv、在同一视频上不同轨道标注多个动作 </li> <li> 易于上手和使用</li></ul> |
<ul><li> 代码可能不稳定,例如有时工具会无响应。</li></ul> | Gitlab 上开源 |
| ANVIL | 分割标注 | <ul> <li> 支持高精度标注,导出开始和结束时间。</li></ul> | <ul><li> 需要 Java,先决条件更重 </li> <li> 与 VIA 相比,上手更困难,有许多规范等。 </li> <li> Java 相关问题可能导致工具难以运行。 </li></ul> |
不开源,但可免费下载 |
| 动作标注工具 | 分割标注 | <ul><li> 在视频关键帧中添加标签</li> <li> 支持高精度到毫秒</li></ul> |
<ul><li> 与 VIA 或 ANVIL 相比,不便得多</li> <li> 未积极开发</li></ul> |
Github 上开源 |
参考资料
- 视频深度学习:2018 年动作识别指南。
- Zhao, H., et al. “Hacs: Human action clips and segments dataset for recognition and temporal localization.” arXiv preprint arXiv:1712.09374 (2019)。
- Kay, Will, et al. “The kinetics human action video dataset.” arXiv preprint arXiv:1705.06950 (2017)。
- Abhishek Dutta 和 Andrew Zisserman。2019。《VIA 图像、音频和视频标注软件》。发表于第 27 届 ACM 国际多媒体会议(MM '19),2019 年 10 月 21 日至 25 日,法国尼斯。ACM,纽约,纽约州,美国,4 页。https://doi.org/10.1145/3343031.3350535。