ai-agents-for-beginners
面向 AI 代理的上下文工程

(点击上方图片观看本课程视频)
了解您正在为其构建 AI 代理的应用程序的复杂性对于构建可靠的代理至关重要。我们需要构建能够有效管理信息的 AI 代理,以解决超越提示工程的复杂需求。
在本课程中,我们将探讨什么是上下文工程及其在构建 AI 代理中的作用。
引言
本课程将涵盖
• 什么是上下文工程,以及它与提示工程有何不同。
• 有效上下文工程的策略,包括如何编写、选择、压缩和隔离信息。
• 常见的上下文故障,这些故障可能会导致您的 AI 代理偏离轨道以及如何修复它们。
学习目标
完成本课程后,您将了解如何
• 定义上下文工程并将其与提示工程区分开来。
• 识别大型语言模型 (LLM) 应用程序中上下文的关键组成部分。
• 应用编写、选择、压缩和隔离上下文的策略以提高代理性能。
• 识别常见的上下文故障,例如中毒、分心、混淆和冲突,并实施缓解技术。
什么是上下文工程?
对于 AI 代理,上下文是驱动 AI 代理规划采取某些行动的因素。上下文工程是确保 AI 代理拥有正确信息以完成任务下一步的实践。上下文窗口的大小有限,因此作为代理构建者,我们需要构建系统和流程来管理上下文窗口中信息的添加、删除和精简。
提示工程与上下文工程
提示工程侧重于一套静态指令,以通过一套规则有效地指导 AI 代理。上下文工程是如何管理一套动态信息,包括初始提示,以确保 AI 代理随着时间的推移拥有所需的信息。上下文工程的核心思想是使这个过程可重复且可靠。
上下文类型
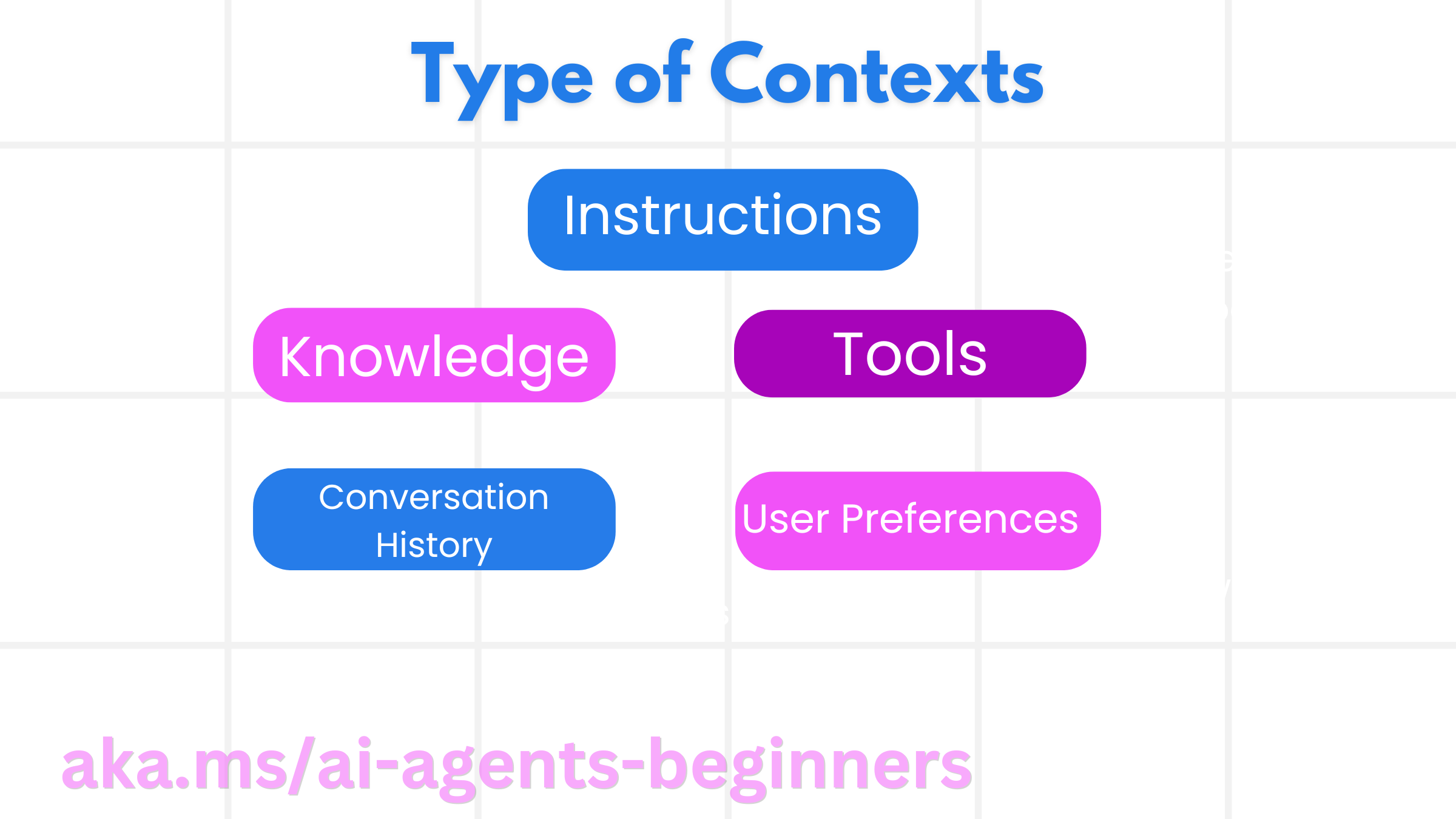
重要的是要记住上下文不仅仅是一件事。AI 代理所需的信息可以来自各种不同的来源,我们有责任确保代理能够访问这些来源。
AI 代理可能需要管理的上下文类型包括
• 指令:这些就像代理的“规则”——提示、系统消息、少量示例(向 AI 展示如何做某事)以及它可以使用的工具的描述。这是提示工程与上下文工程相结合的焦点。
• 知识:这涵盖了从数据库中检索的事实、信息或代理积累的长期记忆。如果代理需要访问不同的知识存储和数据库,这包括集成检索增强生成 (RAG) 系统。
• 工具:这些是代理可以调用的外部函数、API 和 MCP 服务器的定义,以及它从使用它们中获得的反馈(结果)。
• 对话历史:与用户的持续对话。随着时间的推移,这些对话变得更长更复杂,这意味着它们会占用上下文窗口中的空间。
• 用户偏好:随着时间的推移了解到的用户喜好或厌恶信息。这些可以存储并在做出关键决策时调用,以帮助用户。
有效上下文工程的策略
规划策略
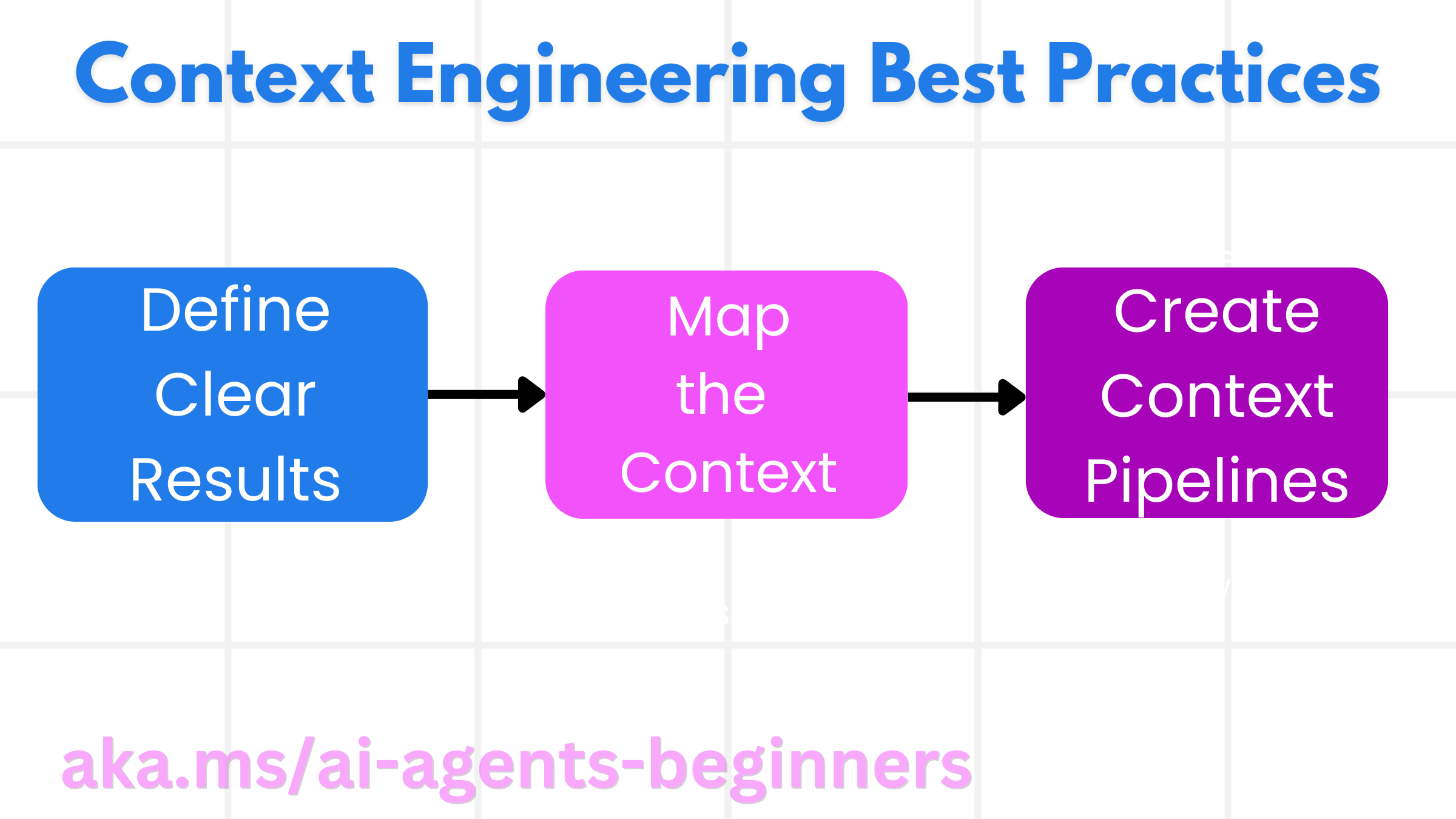
良好的上下文工程始于良好的规划。以下是一种方法,可以帮助您开始思考如何应用上下文工程的概念
- 定义清晰的结果 - 应明确定义分配给 AI 代理的任务结果。回答问题 - “当 AI 代理完成任务时,世界会是什么样子?”换句话说,用户与 AI 代理交互后应该有什么变化、信息或响应。
- 映射上下文 - 定义 AI 代理的结果后,您需要回答“AI 代理需要什么信息才能完成此任务?”的问题。这样您就可以开始映射信息所在位置的上下文。
- 创建上下文管道 - 既然您知道信息在哪里,您就需要回答“代理将如何获取此信息?”的问题。这可以通过各种方式完成,包括 RAG、使用 MCP 服务器和其他工具。
实用策略
规划很重要,但一旦信息开始流入我们代理的上下文窗口,我们需要有实用的策略来管理它
管理上下文
虽然有些信息会自动添加到上下文窗口中,但上下文工程是关于对这些信息采取更积极的作用,这可以通过一些策略来完成
-
代理草稿本 这允许 AI 代理在单个会话期间记录有关当前任务和用户交互的相关信息。这应该存在于上下文窗口之外的文件或运行时对象中,代理以后可以在此会话中根据需要检索。
-
记忆 草稿本适用于管理单个会话上下文窗口之外的信息。记忆使代理能够跨多个会话存储和检索相关信息。这可能包括摘要、用户偏好和未来的改进反馈。
-
压缩上下文 一旦上下文窗口增长并接近其限制,可以使用诸如总结和修剪之类的技术。这包括只保留最相关的信息或删除较旧的消息。
-
多代理系统 开发多代理系统是上下文工程的一种形式,因为每个代理都有自己的上下文窗口。当构建这些系统时,如何共享上下文并将其传递给不同的代理是另一件需要规划的事情。
-
沙盒环境 如果代理需要运行一些代码或处理文档中的大量信息,这可能需要大量的令牌来处理结果。代理可以使用能够运行此代码并只读取结果和其他相关信息的沙盒环境,而不是将所有这些都存储在上下文窗口中。
-
运行时状态对象 这是通过创建信息容器来管理代理需要访问某些信息的情况。对于复杂任务,这将使代理能够逐步存储每个子任务的结果,从而使上下文仅连接到该特定子任务。
上下文工程示例
假设我们希望 AI 代理“帮我预订巴黎之行。”
• 一个只使用提示工程的简单代理可能只会回复:“好的,您什么时候想去巴黎?”它只处理了用户当时提出的直接问题。
• 一个使用所涵盖的上下文工程策略的代理会做更多事情。甚至在回复之前,它的系统可能会
◦ 检查您的日历以查找可用日期(检索实时数据)。
◦ 回忆过去的旅行偏好(来自长期记忆),例如您首选的航空公司、预算,或者您是否喜欢直飞航班。
◦ 识别可用于预订机票和酒店的工具。
- 然后,一个示例回复可能是:“嘿 [您的名字]!我看到您十月的第一周有空。我应该在您通常的 [预算] 预算内寻找 [首选航空公司] 的直飞巴黎航班吗?”这种更丰富、上下文感知的回复展示了上下文工程的力量。
常见的上下文故障
上下文中毒
它是什么:当幻觉(LLM 生成的错误信息)或错误进入上下文并被重复引用时,导致代理追求不可能的目标或制定无意义的策略。
该怎么做:实施上下文验证和隔离。在将信息添加到长期记忆之前对其进行验证。如果检测到潜在中毒,请启动新的上下文线程以防止错误信息传播。
旅行预订示例:您的代理幻想了一个从小型地方机场到遥远的国际城市的直飞航班,而该机场实际上并不提供国际航班。这个不存在的航班详细信息被保存到上下文中。后来,当您要求代理预订时,它会不断尝试寻找这条不可能的路线的机票,导致重复错误。
解决方案:实施一个步骤,在将航班详细信息添加到代理的工作上下文之前,通过实时 API 验证航班是否存在和路线。如果验证失败,错误信息将被“隔离”并且不再使用。
上下文分心
它是什么:当上下文变得太大以至于模型过于关注累积的历史而不是使用它在训练期间学到的东西时,导致重复或无益的动作。模型甚至在上下文窗口满之前就开始犯错。
该怎么做:使用上下文摘要。定期将累积的信息压缩成较短的摘要,保留重要细节,同时删除冗余历史记录。这有助于“重置”焦点。
旅行预订示例:您已经长时间讨论了各种梦想旅行目的地,包括详细回顾您两年前的背包旅行。当您最终要求“下个月给我找一张便宜的机票”时,代理陷入了旧的、不相关的细节中,并不断询问您的背包装备或过去的行程,忽略了您当前的请求。
解决方案:在一定数量的回合之后或当上下文变得太大时,代理应该总结对话中最新和最相关的部分——专注于您当前的旅行日期和目的地——并将该精简的摘要用于下一个 LLM 调用,丢弃不相关的历史聊天记录。
上下文混淆
它是什么:当不必要的上下文(通常是过多可用工具的形式)导致模型生成不良响应或调用不相关的工具。较小的模型尤其容易出现这种情况。
该怎么做:使用 RAG 技术实施工具负载管理。将工具描述存储在向量数据库中,并仅为每个特定任务选择最相关的工具。研究表明,将工具选择限制在 30 个以下。
旅行预订示例:您的代理可以访问数十种工具:book_flight、book_hotel、rent_car、find_tours、currency_converter、weather_forecast、restaurant_reservations 等。您问,“在巴黎出行最好的方式是什么?”由于工具数量众多,代理会感到困惑并尝试在巴黎内部调用book_flight,或者调用rent_car,即使您更喜欢公共交通,因为工具描述可能重叠或者它根本无法分辨出最好的工具。
解决方案:对工具描述使用 RAG。当您询问如何在巴黎出行时,系统会根据您的查询动态检索仅最相关的工具,例如rent_car或public_transport_info,向 LLM 展示一个集中的工具“负载”。
上下文冲突
它是什么:当上下文中存在冲突信息时,导致推理不一致或最终响应不良。这通常发生在信息分阶段到达时,并且早期不正确的假设仍保留在上下文中。
该怎么做:使用上下文修剪和卸载。修剪意味着随着新细节的到来删除过时或冲突的信息。卸载为模型提供了一个单独的“草稿本”工作区来处理信息,而不会混淆主要上下文。
旅行预订示例:您最初告诉您的代理,“我想乘坐经济舱。”在随后的对话中,您改变主意并说,“实际上,这次旅行我们乘坐商务舱吧。”如果两条指令都保留在上下文中,代理可能会收到冲突的搜索结果或对优先考虑哪个偏好感到困惑。
解决方案:实施上下文修剪。当新指令与旧指令冲突时,旧指令将被删除或在上下文中明确覆盖。或者,代理可以使用草稿本在决定之前协调冲突的偏好,确保只有最终、一致的指令指导其行动。
有更多关于上下文工程的问题吗?
加入 Azure AI Foundry Discord,与其他学习者交流,参加办公时间,并解答您的 AI 代理问题。